Agentic SDLC: The Future of Self-Healing, Adaptive Software Systems
Explore the revolutionary shift in software development from traditional methods to an agentic paradigm. Discover how AI agents are moving beyond code generation to autonomously manage, maintain, and evolve complex, self-healing software systems.
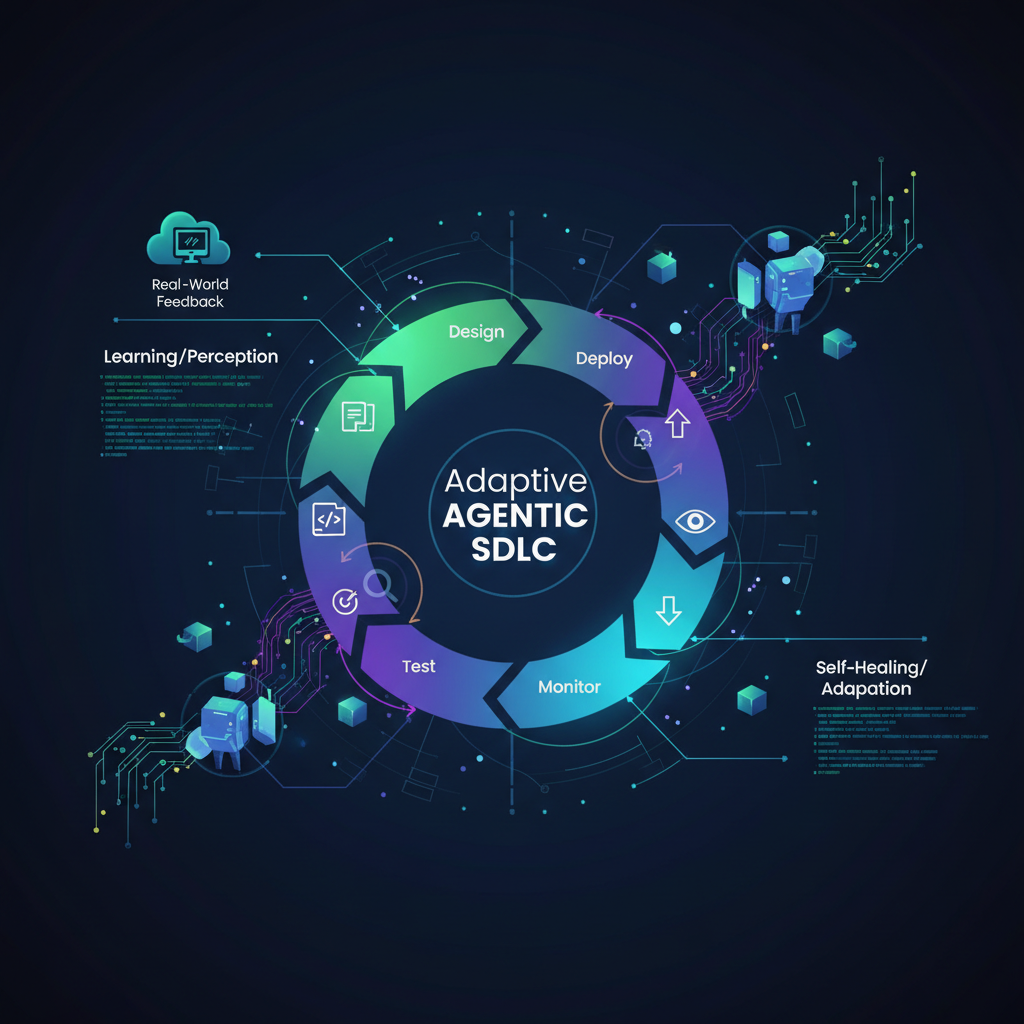
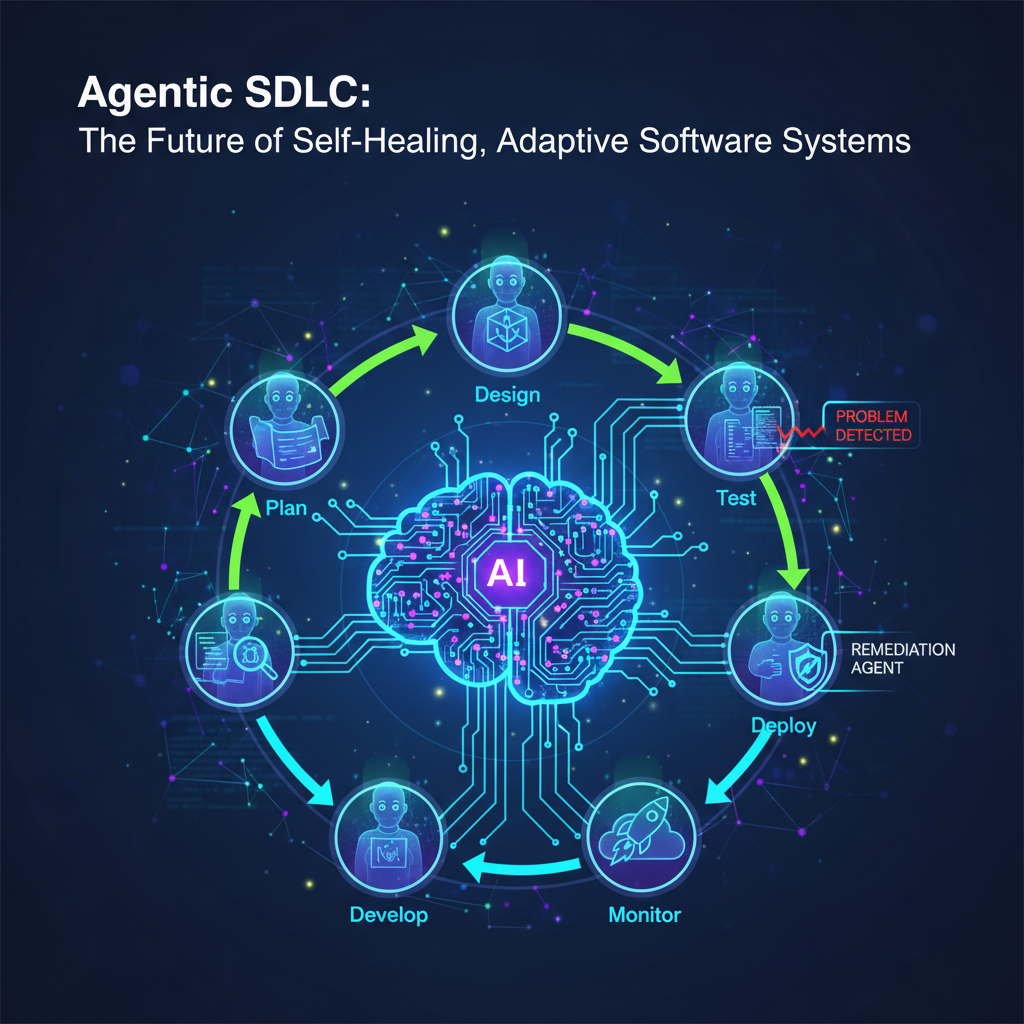
The software development lifecycle (SDLC) has undergone numerous transformations, from waterfall to agile, and now, with the advent of advanced AI, to an agentic paradigm. Initially, the excitement around agentic SDLC centered on autonomous code generation – AI agents writing code based on specifications. While impressive, this was just the beginning. The true frontier lies in agents not just generating code, but autonomously managing, maintaining, and evolving entire software systems, making them self-healing and adaptive. This shift is poised to revolutionize how we build, deploy, and operate complex software, moving beyond reactive fixes to proactive resilience and continuous evolution.
The Imperative for Self-Healing and Adaptive Systems
Modern software systems are a labyrinth of interconnected microservices, distributed databases, and cloud-native infrastructure. This complexity, while enabling scalability and flexibility, introduces inherent fragility. Human operators struggle to keep pace with debugging, performance tuning, and security patching across such vast landscapes. Mean Time To Recovery (MTTR) can be painfully long, and outages costly.
Furthermore, the business landscape is in constant flux. User behavior, market demands, and external API changes require systems to adapt dynamically. Traditional, human-driven SDLCs often lag, leading to missed opportunities or outdated functionality. This is where the concept of a self-healing and adaptive agentic SDLC becomes not just a luxury, but a necessity. It promises to offload the cognitive burden from human teams, allowing systems to autonomously detect, diagnose, and resolve issues, as well as proactively optimize and evolve.
Core Components of a Self-Healing and Adaptive Agentic SDLC
At its heart, this advanced agentic SDLC orchestrates multiple AI agents, each specializing in a crucial aspect of system management. Let's break down these core components:
1. Autonomous Monitoring and Anomaly Detection
The foundation of any self-healing system is its ability to "see" and "understand" its own state. Agents continuously collect and analyze vast streams of telemetry data – logs, metrics, traces, network traffic, and system events.
-
Technical Deep Dive:
- Data Ingestion & Preprocessing: Agents utilize specialized data pipelines to ingest high-volume, high-velocity data from various sources (e.g., Prometheus, OpenTelemetry, Kafka, cloud provider logs). Data is often normalized, enriched, and indexed for efficient querying.
- Machine Learning for Anomaly Detection: Instead of relying solely on static thresholds, agents employ a suite of ML models:
- Time-Series Anomaly Detection: Algorithms like Isolation Forest, Prophet, or LSTM networks learn normal patterns in metrics (CPU usage, request latency, error rates) and flag deviations. For instance, an agent might detect an unusual spike in database connection errors that doesn't correlate with a known deployment or traffic surge.
- Log Anomaly Detection: LLMs or traditional NLP techniques (e.g., clustering, topic modeling) analyze log messages to identify unusual patterns, rare events, or sequences of errors that indicate an impending failure. An agent could spot a sudden increase in "out of memory" errors across multiple microservices, even if individual service metrics appear normal.
- Causal Inference Engines: These advanced components attempt to understand the cause-and-effect relationships within the system. If service A's latency increases, a causal engine might determine if it's due to a bottleneck in its dependency, service B, or an external API call.
- Predictive Analytics: Beyond detecting current anomalies, agents use predictive models to forecast potential failures or performance degradations before they impact users. For example, predicting disk saturation or database connection pool exhaustion based on current trends.
-
Practical Example: An "Observability Agent" constantly monitors a Kubernetes cluster. It notices a gradual increase in HTTP 5xx errors from a specific microservice,
order-processing, coupled with a subtle but consistent rise in its CPU utilization. Traditional alerts might only fire when a threshold is breached, but the Observability Agent, using its ML models, flags this as an "early warning" anomaly, even before user impact is significant.
2. Intelligent Diagnosis and Root Cause Analysis (RCA)
Detecting an anomaly is one thing; understanding why it's happening is another. This is where intelligent diagnosis comes into play. Upon detection, agents don't just alert; they actively investigate.
-
Technical Deep Dive:
- Event Correlation: Agents correlate the detected anomaly with other system events, deployments, configuration changes, and even external factors. They might link the
order-processingservice's issues to a recent deployment of a dependentinventory-managementservice, or to a sudden surge in traffic originating from a marketing campaign. - Knowledge Graphs: A critical component here is a dynamic knowledge graph representing the system's architecture, dependencies, operational history, and known failure modes. Agents query this graph to understand relationships and potential impact areas. For instance, the graph might show that
order-processingdepends oninventory-managementandpayment-gateway, and that a previous issue withinventory-managementmanifested similarly. - LLM-Driven Diagnostic Reasoning: Large Language Models are increasingly powerful for this task. They can ingest raw logs, error messages, and system documentation, then reason about potential causes. An LLM might be prompted with "Explain why
order-processingis experiencing increased 5xx errors, considering recent deployments and system metrics," and it could synthesize a coherent diagnostic narrative. - Probabilistic Graphical Models (PGMs): PGMs like Bayesian Networks can model the probabilistic relationships between different system components and failure modes, allowing agents to infer the most likely root cause given observed symptoms.
- Event Correlation: Agents correlate the detected anomaly with other system events, deployments, configuration changes, and even external factors. They might link the
-
Practical Example: Following the
order-processinganomaly, a "Diagnostic Agent" takes over. It queries the system's knowledge graph to identify dependencies. It then analyzes logs frominventory-managementand finds a pattern of "database connection pool exhausted" errors that started shortly after its last deployment. It correlates this with theorder-processingservice's issues and, using an LLM, generates a hypothesis: "The recent deployment ofinventory-managementintroduced a memory leak, leading to database connection exhaustion, which in turn causedorder-processingto receive 5xx errors due to failed dependency calls."
3. Automated Remediation and Self-Healing
Once a diagnosis is made, the system moves to action. Agents propose and execute corrective measures, aiming to restore normal operation autonomously.
-
Technical Deep Dive:
- Action Planning: Based on the diagnosis, a "Remediation Agent" consults a predefined playbook or uses reinforcement learning to determine the most effective and safest remediation action. This could range from simple restarts to complex code patches.
- Remediation Strategies:
- Rollbacks: Reverting a recent deployment to a stable version.
- Restarts/Reschedules: Restarting a failing service or rescheduling a problematic batch job.
- Scaling Adjustments: Dynamically increasing resources (CPU, memory, instances) for an overloaded service.
- Configuration Changes: Modifying runtime parameters, feature flags, or database connection limits.
- Automated Patching: Applying known security patches or minor code fixes for identified vulnerabilities or bugs.
- Circuit Breakers/Rate Limiting: Temporarily isolating a failing service or limiting traffic to prevent cascading failures.
- Safety and Rollback Mechanisms: Crucially, each remediation action must be accompanied by robust safety checks and immediate rollback capabilities. Agents operate within defined guardrails, and critical actions might require human approval. A "Safety Agent" might monitor the impact of a remediation in real-time and trigger an immediate rollback if conditions worsen.
-
Practical Example: The "Remediation Agent," acting on the diagnosis, proposes two actions:
- Roll back the
inventory-managementservice to its previous stable version. - Temporarily scale up the
order-processingservice to handle potential backlog during the rollback. The agent executes these actions, monitoring key metrics (e.g., 5xx errors, latency) in real-time. If the rollback fails or causes new issues, the Safety Agent immediately triggers a pre-defined contingency plan (e.g., pausing all further automated actions and escalating to a human operator).
- Roll back the
4. Proactive Adaptation and Optimization
Self-healing is about fixing problems; adaptation is about preventing them and continuously improving. Agents go beyond incident response to proactively optimize system performance, resource utilization, and even suggest architectural improvements.
-
Technical Deep Dive:
- Performance Optimization: Agents continuously analyze performance metrics (latency, throughput, resource consumption) and identify bottlenecks. They might suggest and even implement:
- Database query optimizations (e.g., adding an index).
- Code refactoring for inefficient sections (potentially using LLMs to generate improved code snippets).
- Caching strategy adjustments.
- Reinforcement Learning for System Control: RL agents can learn optimal strategies for resource allocation, auto-scaling thresholds, and even dynamic load balancing across different regions based on real-world performance feedback and cost constraints.
- A/B Testing Agents: These agents can autonomously deploy small variations of code or configurations to a subset of users, measure the impact on key performance indicators (KPIs) or user engagement, and then roll out the successful changes more broadly.
- "Evolutionary" Agents: More advanced agents might analyze historical data, user feedback, and business requirements to propose new features or significant architectural changes, effectively driving system evolution.
- Performance Optimization: Agents continuously analyze performance metrics (latency, throughput, resource consumption) and identify bottlenecks. They might suggest and even implement:
-
Practical Example: An "Optimization Agent" observes that a particular database query in the
product-catalogservice is consistently slow, especially during peak hours. It analyzes the query, the database schema, and existing indexes. It then proposes adding a new index to a specific column. After human approval (or if within safe, pre-approved boundaries), it executes the DDL change in a canary environment, monitors performance, and if successful, applies it to production. In another scenario, an RL-driven "Resource Agent" learns that scaling up a specific microservice 5 minutes before a known peak traffic period (e.g., daily sales event) leads to better user experience and lower costs than reactive scaling.
5. Autonomous Testing and Validation
Any change, whether human-initiated or agent-initiated, requires rigorous validation. Agents play a crucial role in ensuring that fixes don't introduce regressions and that optimizations truly improve the system.
-
Technical Deep Dive:
- Test Case Generation: LLMs can generate comprehensive test cases (unit, integration, end-to-end) based on code changes, system specifications, or even incident reports. For a bug fix, an LLM could generate tests specifically targeting the patched area.
- Autonomous Fuzzing: Agents can continuously fuzz APIs and user interfaces with unexpected inputs to uncover vulnerabilities and edge-case bugs.
- Property-Based Testing: Agents can define and verify properties of the system (e.g., "all orders must have a unique ID," "payment processing should always be idempotent") and generate tests to ensure these properties hold true after any change.
- Post-Remediation Validation: After a self-healing action (e.g., a rollback), a "Validation Agent" automatically re-runs a suite of critical tests to confirm the issue is resolved and no new regressions have been introduced.
-
Practical Example: After the
inventory-managementservice rollback, a "Test Agent" automatically triggers a suite of integration tests covering theorder-processingandinventory-managementinteraction. It also generates new synthetic load to simulate peak traffic and verifies that the 5xx error rate has returned to normal and that new orders are being processed successfully.
6. Human-in-the-Loop and Explainability
While the goal is autonomy, complete hands-off operation is often impractical and risky, especially for critical systems. Human oversight and understanding remain paramount.
-
Technical Deep Dive:
- Explainable AI (XAI): Agents must be able to explain their reasoning, proposed actions, and outcomes in a clear, understandable manner. This involves generating natural language summaries of diagnoses, justifications for remediation steps, and impact analyses. Techniques like LIME or SHAP can be adapted to explain model decisions in anomaly detection or root cause analysis.
- Approval Workflows: For critical or high-impact changes (e.g., database schema modifications, production code deployments), agents integrate with human approval workflows. They present the proposed action, its rationale, expected impact, and potential risks to a human operator for review and approval.
- Interactive Dashboards and Alerting: Agents provide rich, interactive dashboards that visualize system state, detected anomalies, ongoing remediation efforts, and their outcomes. Alerting systems are designed to be informative, providing context and actionable insights rather than just raw data.
-
Practical Example: Before the "Optimization Agent" applies the new database index, it presents a detailed report to the DBA team: "Proposed action: Add index
idx_product_idtoproduct_catalog.productstable. Rationale: Queryget_product_by_idis causing 300ms latency at peak. Expected impact: Reduce query latency by 80%, estimated CPU reduction 10%. Risks: Minor write performance impact during index creation, negligible long-term. Validation: Performance tests show 90% latency reduction in staging." The DBA can then approve or reject the change.
Recent Developments and Emerging Trends
The rapid advancements in AI, particularly LLMs, are accelerating the realization of this vision:
- LLM Integration Everywhere: LLMs are becoming the "brains" of these agentic systems, understanding natural language requirements, analyzing unstructured logs, generating diagnostic narratives, proposing code fixes, and even generating comprehensive test suites.
- Multi-Agent Architectures: The trend is moving away from monolithic agents to specialized, collaborative multi-agent systems. A "Security Agent" might collaborate with a "Network Agent" to diagnose a suspected DDoS attack, then coordinate with a "Remediation Agent" to apply traffic filtering rules.
- Reinforcement Learning for System Control: RL is proving effective in learning optimal, dynamic strategies for resource management, load balancing, and even dynamic code modification in complex, unpredictable environments.
- Knowledge Graphs and Semantic Reasoning: Building rich, interconnected knowledge bases about the system's architecture, dependencies, and operational history is crucial for intelligent diagnosis and planning, enabling agents to reason about the system like an experienced engineer.
- Focus on Safety and Guardrails: As agents gain more autonomy, the emphasis on safety, human oversight, and robust rollback mechanisms is paramount. Sandbox environments, formal verification methods for agent actions, and clear human approval gates are becoming standard.
- From "DevOps Copilots" to "Autonomous Operations": The trajectory is clear: AI assisting human operators is evolving into AI taking direct operational responsibilities, freeing up human engineers for more creative and strategic tasks.
Practical Applications and Benefits
The implications of self-healing and adaptive agentic SDLC are profound:
- Reduced Operational Costs: Automation of routine debugging, maintenance, and optimization significantly reduces the need for human intervention, freeing up engineers.
- Improved System Uptime and Reliability: Faster incident resolution (reduced MTTR) and proactive issue prevention lead to higher availability and a more reliable user experience.
- Faster Feature Delivery: Agents can automate refactoring, optimization, and even some bug fixes, allowing development teams to focus more on new features and innovation.
- Enhanced Security Posture: Automated vulnerability scanning, patching, and real-time threat response significantly strengthen system security.
- Complex System Management: This approach makes it feasible to manage highly distributed, dynamic, and complex cloud-native architectures that would otherwise overwhelm human teams.
- Research Opportunities: This field is ripe for innovation, offering numerous research avenues in multi-agent coordination, explainable AI, robust safety protocols, and generalization capabilities.
Challenges and Future Directions
Despite the immense promise, significant challenges remain:
- Trust and Explainability: Building human trust in autonomous systems that make critical changes requires agents to be transparent and explain their reasoning clearly. How do we ensure they don't operate as black boxes?
- Safety and Control: Preventing unintended consequences or "runaway agents" is critical. Defining clear boundaries, implementing robust human override mechanisms, and formal verification of agent actions are essential.
- Generalization: Can agents adapt to entirely new types of failures or system architectures without extensive retraining? The ability to reason about novel situations is a key challenge.
- Data Scarcity: Training robust diagnostic and remediation models often requires vast amounts of historical incident data, which might not always be available, especially for new systems or rare failure modes.
- Ethical Implications: As systems gain more autonomy, who is ultimately responsible when an autonomous system makes a mistake that leads to business impact or harm? This raises complex legal and ethical questions.
Conclusion
The journey from autonomous code generation to self-healing and adaptive agentic SDLC marks a pivotal moment in software engineering. We are moving towards a future where software systems are not just built, but are living entities that can observe, understand, diagnose, heal, and evolve themselves. This paradigm shift promises unprecedented levels of resilience, efficiency, and adaptability, transforming DevOps and SRE practices. While challenges related to trust, safety, and explainability remain, the rapid advancements in AI are bringing this futuristic vision closer to reality, paving the way for truly intelligent and autonomous software ecosystems. The next generation of software will not just run; it will thrive, adapt, and heal, ushering in an era of unparalleled system robustness and innovation.