Bridging the Gap: Fine-Tuning Large Language Models for Specialized Domains
Large Language Models (LLMs) excel at general tasks but often lack precision in specialized domains. This post explores the challenges and necessity of fine-tuning models like GPT-4 and Llama 2 to acquire the deep, domain-specific knowledge required for practical, real-world applications, moving beyond their general intelligence.
The era of Large Language Models (LLMs) has ushered in unprecedented capabilities in natural language understanding and generation. From creative writing to complex problem-solving, models like GPT-4, Llama 2, and Mistral have demonstrated a remarkable ability to handle a vast array of general-purpose tasks. However, the true power of these models often lies dormant when confronted with highly specialized domains. Imagine asking a general-purpose LLM to draft a legal brief, summarize a medical research paper, or generate code in a proprietary internal framework – the results, while often coherent, frequently lack the precision, nuance, and domain-specific knowledge required for practical application.
This gap between general intelligence and domain-specific expertise has historically been a significant hurdle. Full fine-tuning of multi-billion parameter models is an endeavor reserved for well-funded research labs and tech giants, demanding immense computational resources, vast datasets, and considerable time. For the vast majority of organizations and individual practitioners, this barrier has made the promise of tailored LLMs seem out of reach.
But what if you could adapt these colossal models to your specific needs with a fraction of the cost, computational power, and data? What if you could imbue them with the specialized knowledge of your industry, the unique voice of your brand, or the intricate logic of your internal systems, without breaking the bank or needing a supercomputer? This is precisely the revolution being driven by efficient and accessible fine-tuning techniques, transforming LLMs from general-purpose marvels into highly specialized, impactful tools for domain-specific applications.
The Challenge: Bridging the General-to-Specific Gap
General-purpose LLMs are trained on colossal datasets encompassing the entirety of the internet, allowing them to learn broad patterns of language, facts, and reasoning. This breadth is their strength, but also their limitation. When faced with a specific domain, they often exhibit several shortcomings:
- Lack of Domain Knowledge: They might not understand specialized terminology, industry-specific jargon, or nuanced concepts unique to a particular field (e.g., medical diagnoses, legal precedents, financial instruments).
- Stylistic Mismatch: The generated text might not adhere to the required tone, formality, or structure expected in a specific professional context (e.g., academic papers, corporate communications, technical documentation).
- Hallucinations and Inaccuracies: Without sufficient domain-specific training, models can confidently generate plausible-sounding but factually incorrect information, especially in areas where precision is paramount.
- Data Privacy and Security Concerns: Enterprises often cannot send sensitive proprietary data to external API-based LLMs due to compliance, privacy, or security regulations. This necessitates local or private cloud deployment and fine-tuning.
- Computational Cost of Full Fine-Tuning: Retraining or fully fine-tuning a model with hundreds of billions of parameters requires immense GPU clusters, memory, and time, making it economically unfeasible for most.
These challenges highlight the critical need for methods that allow practitioners to efficiently adapt LLMs to their unique data and requirements.
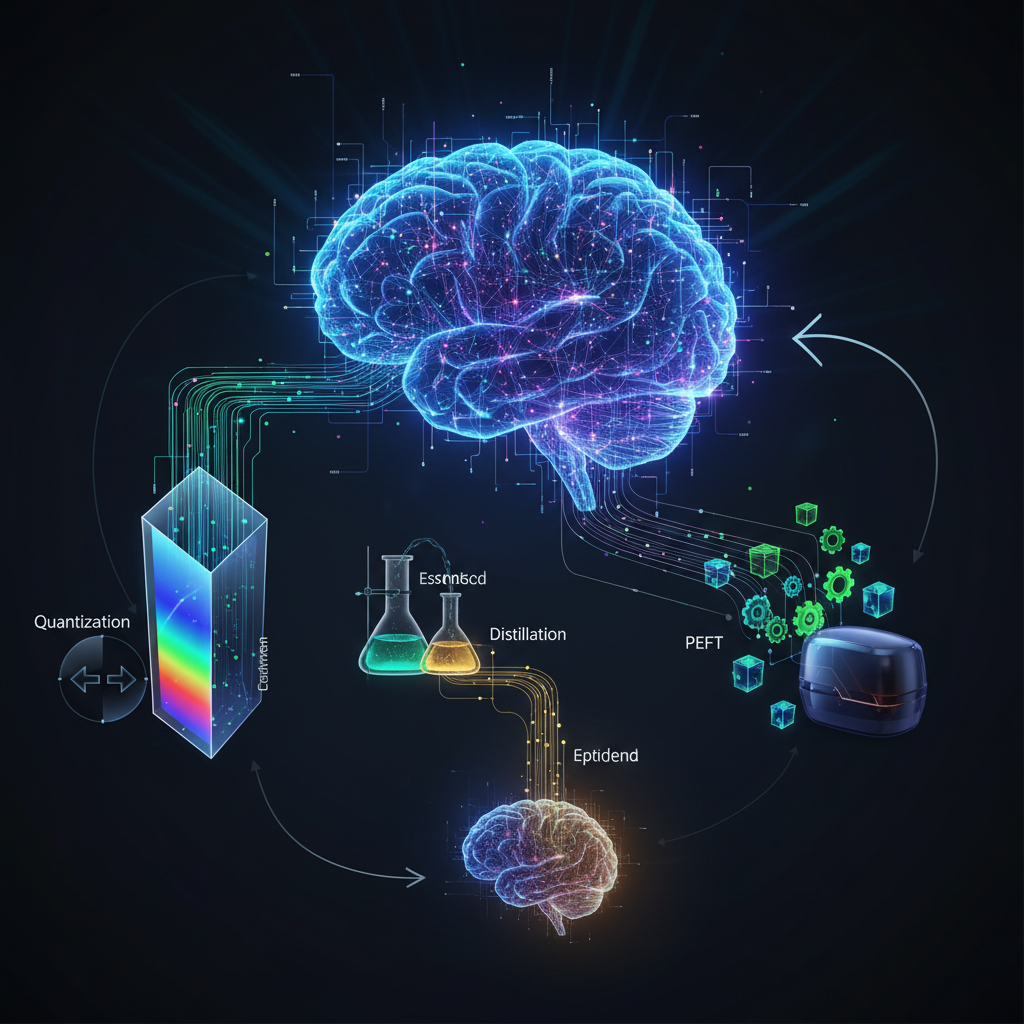
The Revolution: Parameter-Efficient Fine-Tuning (PEFT)
The game-changer in making LLM adaptation accessible is Parameter-Efficient Fine-Tuning (PEFT). Instead of updating all (or even most) of the billions of parameters in a pre-trained LLM, PEFT methods focus on training only a small subset of new parameters, or cleverly modifying existing ones, to achieve domain specialization. This dramatically reduces computational cost, memory footprint, and storage requirements.
Let's dive into some of the most prominent PEFT techniques:
1. LoRA (Low-Rank Adaptation)
LoRA is arguably the most popular and impactful PEFT method. It operates on the principle that the change in weights during fine-tuning often has a low "intrinsic rank." Instead of directly fine-tuning the full weight matrices of a pre-trained model, LoRA injects small, trainable low-rank matrices into the transformer layers.
Here's how it works: For a pre-trained weight matrix $W_0 \in \mathbb{R}^{d \times k}$, LoRA proposes to update it by adding a low-rank decomposition: $W_0 + \Delta W = W_0 + BA$, where $B \in \mathbb{R}^{d \times r}$ and $A \in \mathbb{R}^{r \times k}$. Here, $r$ is the "rank" and is typically much smaller than $d$ or $k$ (e.g., 4, 8, 16, 32, 64).
During fine-tuning, $W_0$ remains frozen. Only the matrices $A$ and $B$ are trained. The input to the layer ($x$) is transformed by $(W_0 + BA)x = W_0x + BAx$. The output of $BAx$ is scaled by a factor $\alpha/r$ to account for the rank.
Why it's efficient:
- The number of trainable parameters is drastically reduced. For a matrix of size $d \times k$, full fine-tuning requires $d \times k$ parameters. LoRA requires $d \times r + r \times k$ parameters. If $r \ll d, k$, this is a massive reduction.
- The original pre-trained model weights remain untouched, allowing for easy swapping of LoRA adapters for different tasks without storing multiple full copies of the base model.
- During inference, the fine-tuned weights can be merged back into the original weights ($W_0 + BA$), incurring no additional latency.
Example (Conceptual PyTorch with Hugging Face PEFT):
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
# 1. Load a base LLM
model_name = "mistralai/Mistral-7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 2. Define LoRA configuration
# target_modules often include 'q_proj', 'k_proj', 'v_proj', 'o_proj' for attention layers
lora_config = LoraConfig(
r=8, # LoRA attention dimension
lora_alpha=16, # Alpha parameter for LoRA scaling
target_modules=["q_proj", "v_proj"], # Modules to apply LoRA to
lora_dropout=0.1, # Dropout probability for LoRA layers
bias="none", # Whether to train bias parameters
task_type=TaskType.CAUSAL_LM # Task type for language modeling
)
# 3. Apply LoRA to the base model
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: 4,194,304 || all params: 7,247,433,728 || trainable%: 0.05787265215904033
# Now, 'model' is ready for training. Only the LoRA adapters will be updated.
# The number of trainable parameters is a tiny fraction of the total.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
# 1. Load a base LLM
model_name = "mistralai/Mistral-7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 2. Define LoRA configuration
# target_modules often include 'q_proj', 'k_proj', 'v_proj', 'o_proj' for attention layers
lora_config = LoraConfig(
r=8, # LoRA attention dimension
lora_alpha=16, # Alpha parameter for LoRA scaling
target_modules=["q_proj", "v_proj"], # Modules to apply LoRA to
lora_dropout=0.1, # Dropout probability for LoRA layers
bias="none", # Whether to train bias parameters
task_type=TaskType.CAUSAL_LM # Task type for language modeling
)
# 3. Apply LoRA to the base model
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: 4,194,304 || all params: 7,247,433,728 || trainable%: 0.05787265215904033
# Now, 'model' is ready for training. Only the LoRA adapters will be updated.
# The number of trainable parameters is a tiny fraction of the total.
2. QLoRA (Quantized LoRA)
QLoRA takes LoRA a step further by applying it to a quantized base model. Quantization reduces the precision of model weights (e.g., from 32-bit floats to 8-bit or 4-bit integers), drastically cutting down memory usage and potentially speeding up computation.
QLoRA specifically introduces:
- 4-bit NormalFloat (NF4): A new data type optimized for normally distributed weights, offering better performance than standard 4-bit floats.
- Double Quantization: Quantizing the quantization constants themselves, saving even more memory.
- Paged Optimizers: Using NVIDIA's unified memory to prevent out-of-memory errors during gradient checkpointing, enabling training of very large models on consumer GPUs.
By combining LoRA with 4-bit quantization, QLoRA makes it possible to fine-tune models like Llama 2 70B on a single high-end GPU (e.g., an A100 80GB or even a 3090 24GB with some sacrifices). This is a monumental achievement for accessibility.
3. Prompt Tuning / Prefix Tuning
Unlike LoRA which modifies internal weights, Prompt Tuning and Prefix Tuning work by adding a small, trainable "soft prompt" or "prefix" to the input sequence. This prefix is learned during fine-tuning and guides the pre-trained LLM's behavior without altering its core weights.
- Prompt Tuning: Adds a short, trainable vector sequence to the beginning of the input embeddings. This soft prompt is task-specific and optimized to elicit the desired output from the frozen LLM.
- Prefix Tuning: A generalization of prompt tuning, where the trainable prefix is added to every layer of the transformer network, not just the input. This provides more expressive power.
These methods are extremely parameter-efficient as they only train the small prompt/prefix vectors. They are particularly useful for tasks where the core knowledge of the LLM is sufficient, but it needs guidance on how to apply that knowledge to a specific task or format.
4. Adapter Layers
Adapter layers involve inserting small, fully connected neural network modules between the existing layers of the pre-trained transformer. During fine-tuning, only these adapter layers are trained, while the original LLM weights remain frozen. Each adapter typically consists of a down-projection, a non-linear activation, and an up-projection.
Adapter layers are more parameter-efficient than full fine-tuning but generally less so than LoRA or prompt tuning. However, they can be highly effective and offer a good balance between expressiveness and efficiency.
Quantization Techniques Beyond QLoRA
While QLoRA integrates 4-bit NF4 quantization, other quantization techniques are crucial for deploying and even training LLMs efficiently:
- 8-bit Quantization (e.g., bitsandbytes): Reduces model weights to 8-bit integers, significantly cutting memory usage (by 75%) with minimal performance degradation. This is often used for inference and can be combined with PEFT for training.
- 4-bit Quantization (General): Further reduces memory but can lead to more noticeable performance drops if not carefully implemented (like NF4 in QLoRA).
- Sparsity: Pruning techniques that remove less important weights from the model, making it smaller and faster.
These techniques are not just for fine-tuning; they are essential for making LLMs runnable on consumer hardware for inference, democratizing access to powerful models.
Instruction Tuning for Domain-Specific Alignment
Beyond merely adapting to domain terminology, many applications require LLMs to follow instructions effectively within that domain. This is where instruction tuning comes in. It involves fine-tuning an LLM on datasets of (instruction, input, output) triplets, teaching it to understand and execute specific commands.
For domain-specific applications, this means:
- Curating Domain-Specific Instructions: Creating datasets where instructions are tailored to the domain (e.g., "Summarize this medical case study," "Draft a legal clause for X," "Generate a Python function for Y").
- Leveraging Existing Datasets: Using open-source instruction datasets like Alpaca, Dolly, ShareGPT, or OpenAssistant for initial instruction tuning, and then further fine-tuning with domain-specific data.
- Reinforcement Learning from Human Feedback (RLHF) / Direct Preference Optimization (DPO): For truly aligned and helpful models, especially in sensitive domains, techniques like RLHF or DPO can be applied after initial instruction tuning to further refine the model's responses based on human preferences. While RLHF is complex, DPO offers a more accessible alternative for aligning models.
Practical Applications and Use Cases
The ability to efficiently fine-tune LLMs unlocks a vast array of domain-specific applications across industries:
- Healthcare:
- Clinical Note Generation: Fine-tuning models on electronic health records (EHR) to generate structured clinical notes from dictated or transcribed patient encounters.
- Medical Q&A: Creating chatbots that can answer patient or clinician queries based on specific medical guidelines, research papers, or drug information.
- Research Summarization: Summarizing complex medical literature, clinical trials, or drug discovery reports.
- Legal:
- Document Drafting: Generating initial drafts of contracts, legal briefs, or patents based on specific parameters and precedents.
- Case Law Summarization: Summarizing lengthy legal documents, identifying key arguments, and extracting relevant case law.
- Legal Research Assistant: Answering legal questions by referencing specific statutes, regulations, or case databases.
- Finance:
- Market Analysis and Reporting: Generating summaries of financial news, market trends, or company reports.
- Customer Service Bots: Building highly specialized chatbots for banking or investment firms that understand complex financial products and regulations.
- Fraud Detection Support: Generating explanations for suspicious transactions or flagging anomalies based on financial data patterns.
- Customer Support & Sales:
- Product-Specific Chatbots: Training LLMs on extensive product documentation, FAQs, and internal knowledge bases to provide accurate and consistent support.
- Sales Enablement: Generating personalized sales pitches, email responses, or product descriptions tailored to specific customer needs.
- Software Development:
- Code Generation & Autocompletion: Fine-tuning models on an organization's internal codebase, coding standards, and APIs to generate more relevant and accurate code suggestions.
- Documentation Generation: Automatically generating API documentation, user manuals, or code comments.
- Bug Description & Resolution: Summarizing bug reports and suggesting potential fixes based on historical data.
- Education:
- Personalized Learning: Generating tailored explanations, practice problems, or feedback based on a student's learning style and progress in a specific subject.
- Content Creation: Developing specialized educational content, quizzes, or lesson plans for niche topics.
The Open-Source Ecosystem: Democratizing Access
The rapid advancements in PEFT would not be as impactful without the vibrant open-source ecosystem. Key tools and frameworks have made these techniques accessible to a wider audience:
- Hugging Face
PEFTLibrary: This library is a cornerstone, providing easy-to-use implementations of LoRA, Prompt Tuning, Prefix Tuning, and other PEFT methods. It seamlessly integrates with the Hugging Facetransformerslibrary. - Hugging Face
bitsandbytes: Crucial for 8-bit and 4-bit quantization, enabling larger models to fit into memory for both training and inference. - Hugging Face
transformers: The foundational library for working with transformer models, providing pre-trained models, tokenizers, and training utilities. Axolotl: A popular training script that simplifies the process of fine-tuning LLMs (especially Llama variants) using PEFT and quantization techniques. It abstracts away much of the complexity of distributed training and data preparation.TuningFork: Another framework aimed at simplifying efficient LLM fine-tuning.- Open-Source LLMs: Models like Llama 2, Mistral, Falcon, and others provide powerful base models that can be freely adapted and deployed.
These tools, combined with a growing community of practitioners, are democratizing the ability to build and deploy specialized LLMs.
Evaluation: Beyond General Benchmarks
Evaluating fine-tuned LLMs requires moving beyond general benchmarks like GLUE or SuperGLUE, which may not capture domain-specific nuances. Effective evaluation strategies include:
- Domain-Specific Metrics:
- Accuracy/F1-score: For classification or information extraction tasks.
- ROUGE/BLEU: For summarization or translation, adapted to domain-specific language.
- Custom Metrics: Developing metrics that measure adherence to specific guidelines, factual correctness within the domain, or stylistic consistency.
- Human Evaluation: The gold standard for many generative tasks. Domain experts can assess the quality, accuracy, relevance, and safety of the model's outputs.
- Adversarial Testing: Probing the model with challenging or edge-case inputs to identify weaknesses or biases.
- Task-Specific Benchmarks: Creating small, representative datasets of domain-specific tasks with expert-annotated ground truth.
Trade-offs and Considerations
While PEFT techniques offer immense benefits, it's crucial to understand the trade-offs:
- Performance vs. Efficiency: More aggressive quantization (e.g., 4-bit) or very low LoRA ranks (e.g., r=4) can sometimes lead to a slight degradation in performance compared to full fine-tuning, especially for highly complex tasks. The optimal balance needs to be found through experimentation.
- Data Quality and Quantity: While PEFT can be more data-efficient than full fine-tuning, high-quality, relevant domain-specific data is still paramount. "Garbage in, garbage out" applies here more than ever.
- Hyperparameter Tuning: PEFT methods introduce new hyperparameters (e.g., LoRA rank
r,lora_alpha,target_modules). Careful tuning of these parameters is essential for optimal results. - Base Model Choice: The performance of the fine-tuned model is heavily dependent on the capabilities of the pre-trained base model. A stronger base model generally leads to a stronger fine-tuned model.
- Deployment Complexity: While PEFT adapters are small, managing multiple adapters for different tasks and ensuring efficient loading/unloading during inference can add complexity to deployment.
Conclusion
The landscape of Large Language Models is evolving at an astonishing pace, and the ability to efficiently and accessibly fine-tune these models is arguably one of the most significant developments for practical AI adoption. Parameter-Efficient Fine-Tuning techniques like LoRA and QLoRA, coupled with robust open-source tools, have shattered the barriers of computational cost and expertise, making domain-specific LLM adaptation a reality for organizations and individuals of all sizes.
We are witnessing a shift from generic AI to highly specialized, intelligent agents that can seamlessly integrate into specific workflows, understand nuanced domain language, and deliver precise, relevant outputs. For AI practitioners and enthusiasts, mastering these techniques is no longer a niche skill but a fundamental requirement for building impactful, cost-effective, and truly transformative LLM solutions across virtually every industry. The future of LLMs is not just about bigger models, but smarter, more tailored ones that serve the unique needs of a diverse world.