Efficient LLMs: Bringing Advanced AI to the Edge and On-Device
Explore the critical shift towards efficient and explainable Large Language Models (LLMs) for edge and on-device deployment. Discover how this innovation democratizes AI, enhances privacy, reduces environmental impact, and unlocks new applications beyond cloud constraints.
The era of Large Language Models (LLMs) has ushered in unprecedented capabilities, transforming how we interact with information, automate tasks, and generate creative content. From crafting compelling marketing copy to assisting with complex coding challenges, LLMs have demonstrated a versatility that was once the stuff of science fiction. However, this power comes at a significant cost: immense computational resources, vast energy consumption, and a reliance on cloud infrastructure. This reality has sparked a critical new frontier in AI research: the pursuit of efficient and explainable LLMs for edge/on-device deployment and specialized applications.
This isn't just about making LLMs "a little faster" or "a little smaller." It's a fundamental shift towards democratizing advanced AI, enhancing privacy, reducing environmental impact, and unlocking a myriad of new applications that were previously impossible due to latency, connectivity, or cost constraints.
The Cloud Conundrum: Why On-Device LLMs Are Essential
The current paradigm for deploying powerful LLMs largely relies on centralized cloud servers. While effective for many applications, this approach presents several significant challenges:
- Computational Cost and Energy Footprint: Training and running multi-billion parameter models demand enormous computational power, leading to substantial energy consumption and a growing carbon footprint. Each API call to a large cloud model incurs a cost, which can quickly become prohibitive for high-volume or continuous inference.
- Latency and Connectivity: Cloud-dependent LLMs suffer from network latency. For real-time applications like autonomous driving, industrial automation, or instantaneous conversational AI, even a few hundred milliseconds of delay can be unacceptable. Furthermore, constant internet connectivity is a prerequisite, limiting deployment in remote areas, air-gapped environments, or situations with unreliable networks.
- Privacy and Security Concerns: Sending sensitive personal, financial, or proprietary data to third-party cloud services raises significant privacy and security issues. Industries like healthcare, finance, and defense often have strict regulatory requirements that prohibit or severely restrict off-device data processing.
- Customization and Specialization: While large general-purpose LLMs are powerful, many applications require highly specialized knowledge or unique interaction patterns. Fine-tuning massive models for niche tasks can still be resource-intensive, and deploying these specialized versions efficiently is a challenge.
These limitations underscore the urgent need for a new approach: bringing the power of LLMs closer to the data, directly onto devices, and into specialized, resource-constrained environments.
The Arsenal of Efficiency: Techniques for Smaller, Faster LLMs
The journey towards efficient on-device LLMs involves a multi-pronged strategy, leveraging advancements in model architecture, training methodologies, and deployment techniques.
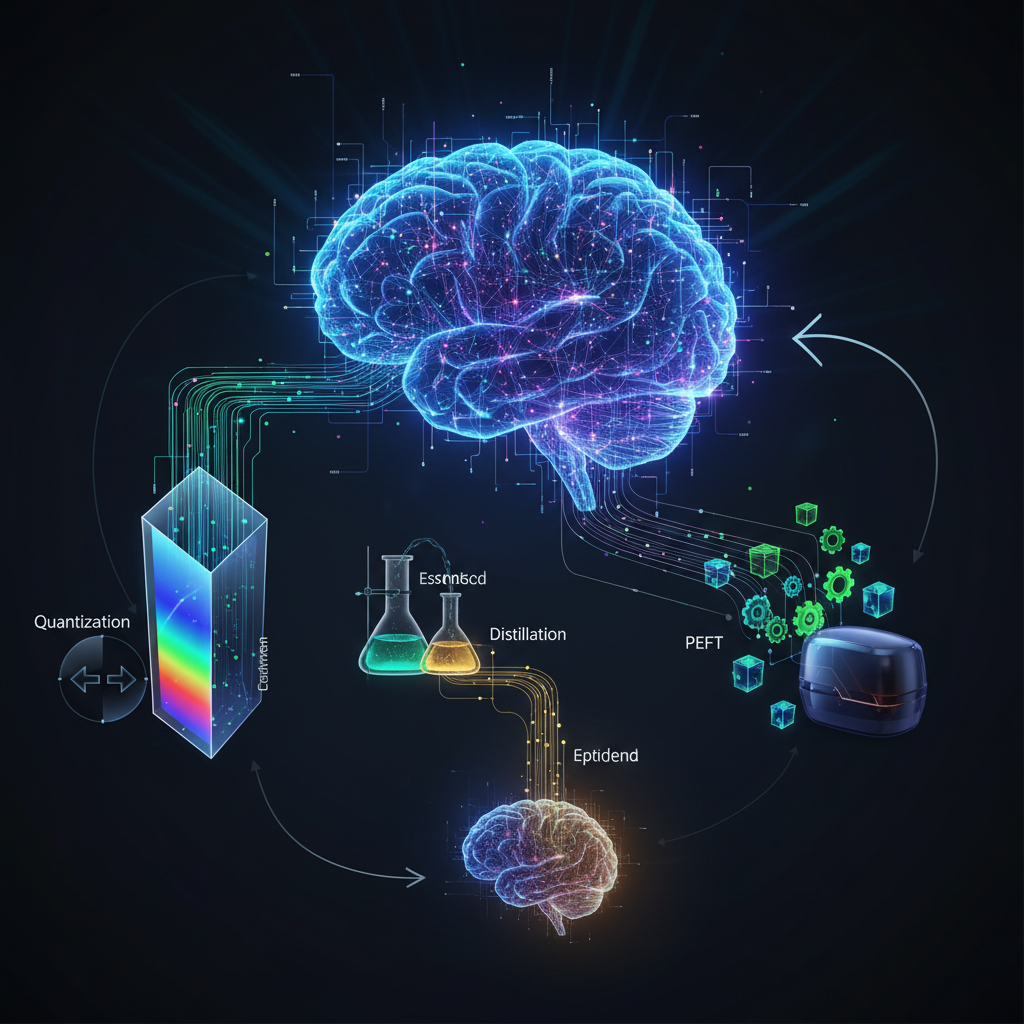
1. Model Compression Techniques
These methods aim to reduce the size and computational requirements of pre-trained LLMs while maintaining performance.
-
Quantization: This is perhaps the most widely adopted technique for on-device deployment. Quantization reduces the precision of the numerical representations of model weights and activations. Instead of using 32-bit floating-point numbers (FP32), models can be quantized to 16-bit (FP16), 8-bit (INT8), 4-bit (INT4), or even 2-bit integers.
- How it works: Lower precision numbers require less memory to store and fewer clock cycles to process. For example, moving from FP32 to INT8 can reduce memory footprint and bandwidth requirements by 4x.
- Example: Running a 7B parameter model in FP16 might require ~14GB of VRAM. Quantizing it to INT4 could bring that down to ~3.5GB, making it feasible for devices with limited memory. Libraries like
bitsandbytesandGGML/GGUF(used byllama.cpp) are popular for performing dynamic or static quantization. - Challenges: Aggressive quantization (e.g., below 4-bit) can sometimes lead to a noticeable drop in model accuracy, requiring careful calibration and post-training quantization-aware fine-tuning.
-
Pruning: This technique removes redundant or less important weights, neurons, or even entire layers from a neural network.
- How it works: Pruning typically involves training a dense model, identifying connections with weights below a certain threshold (magnitude-based pruning), and then retraining the sparse model to recover accuracy. Structural pruning removes entire channels or filters, leading to more regular sparse structures that are easier for hardware to accelerate.
- Example: Imagine a large neural network as a dense forest. Pruning is like selectively cutting down trees that contribute least to the overall health of the forest, making it sparser and easier to navigate without losing its essential function.
- Challenges: Finding the optimal pruning strategy without significant performance degradation is an active research area. Irregular sparsity patterns can also be challenging for general-purpose hardware to exploit efficiently.
-
Knowledge Distillation: This method involves training a smaller, more efficient "student" model to mimic the behavior of a larger, more powerful "teacher" model.
- How it works: The student model is trained not just on the ground truth labels but also on the "soft targets" (probability distributions over classes) provided by the teacher model. This allows the student to learn the nuances and generalizations captured by the larger model.
- Example: A massive GPT-4 equivalent (teacher) could be used to generate responses, classifications, or embeddings, which then serve as training data for a much smaller, specialized student model (e.g., a few hundred million parameters). The student learns to replicate the teacher's outputs, often achieving comparable performance for specific tasks at a fraction of the size.
- Benefits: Can significantly reduce model size while maintaining high accuracy, especially for specific downstream tasks.
2. Parameter-Efficient Fine-Tuning (PEFT)
Traditional fine-tuning of LLMs involves updating all parameters, which is computationally expensive and requires storing a full copy of the model for each fine-tuned task. PEFT methods address this by only updating a small subset of parameters or introducing a few new trainable parameters.
-
LoRA (Low-Rank Adaptation): One of the most popular PEFT techniques.
- How it works: LoRA injects small, trainable matrices into the transformer layers. Instead of fine-tuning the original large weight matrices, only these much smaller "adapter" matrices are updated during training. The original pre-trained weights remain frozen.
- Benefits: Dramatically reduces the number of trainable parameters (often by 1000x or more), leading to faster training, lower memory consumption, and the ability to store multiple task-specific LoRA adapters without duplicating the entire base model.
- Example: Fine-tuning a 7B parameter LLM might typically require updating all 7 billion parameters. With LoRA, you might only train a few million parameters, making it feasible on consumer-grade GPUs and allowing for rapid experimentation with different datasets.
- Variants: QLoRA combines LoRA with 4-bit quantization, allowing for fine-tuning massive models (e.g., 65B parameters) on a single GPU.
-
Prefix Tuning and Prompt Tuning: These methods involve adding a small sequence of trainable "prefix" or "prompt" tokens to the input, which are optimized during fine-tuning. The main LLM weights remain frozen.
- How it works: These trainable tokens effectively guide the LLM's behavior for a specific task without modifying its core knowledge.
- Benefits: Extremely parameter-efficient, often requiring only a few thousand trainable parameters.
3. Architectural Innovations: The Rise of Small Language Models (SLMs)
Beyond compressing existing large models, a new wave of research focuses on designing models that are inherently small and efficient from the ground up.
- Purpose-Built SLMs: Models like Microsoft's Phi-2, Google's Gemma, and Mistral's 7B models are not just scaled-down versions of larger LLMs. They often incorporate novel architectural choices, highly curated training data, and optimized training strategies to achieve impressive performance despite their compact size.
- Example: Phi-2, with 2.7 billion parameters, demonstrates reasoning capabilities comparable to models 10-20 times its size, partly due to its "textbook-quality" training data. Mistral 7B consistently outperforms larger models like Llama 2 13B across various benchmarks.
- Mixture of Experts (MoE) for Inference Efficiency: While MoE models (e.g., Mixtral 8x7B) have a large total number of parameters, they achieve inference efficiency by only activating a small subset of "expert" sub-networks for each input. This means that while the model is large, the computational cost per token is significantly lower than a dense model of equivalent total parameter count.
- Challenge for Edge: The primary challenge is still the total parameter count. While inference is sparse, the entire model (all experts) must still be loaded into memory. Research is ongoing to make sparse MoE models truly edge-deployable.
4. Hardware-Software Co-design
The efficiency revolution is also driven by specialized hardware.
- AI Accelerators: Dedicated chips like Neural Processing Units (NPUs), Tensor Processing Units (TPUs), and various edge AI accelerators are optimized for matrix multiplications and other operations common in neural networks.
- Memory Optimization: These chips often feature high-bandwidth, low-latency memory close to the processing units, which is crucial for LLM inference.
- Quantization Support: Many modern accelerators have native support for lower precision data types (INT8, INT4), making quantized models run even faster.
The Explainability Imperative: Trust and Transparency at the Edge
As LLMs move into critical applications on devices and in specialized environments, understanding why they make certain decisions becomes paramount. Explainable AI (XAI) for efficient models is not just a desirable feature; it's a necessity for trust, safety, and compliance.
-
Why Explainability Matters for Edge LLMs:
- Debugging and Reliability: If an on-device LLM in a medical device or autonomous vehicle makes an error, understanding the root cause is vital for debugging and ensuring reliability.
- Trust and User Acceptance: Users are more likely to trust and adopt AI systems if they can understand their rationale, especially in sensitive domains.
- Regulatory Compliance: Many industries require AI systems to be auditable and explainable to meet regulatory standards (e.g., GDPR's "right to explanation").
- Bias Detection and Mitigation: Explanations can help identify and mitigate biases that might be present in the model or its training data, which is crucial for fair and ethical deployment.
-
XAI Techniques for Efficient Models:
- Attention Mechanisms: Transformer-based LLMs inherently provide some level of interpretability through their attention weights, showing which parts of the input were most relevant to a particular output. Visualizing these attention maps can offer insights.
- LIME (Local Interpretable Model-agnostic Explanations) & SHAP (SHapley Additive exPlanations): These model-agnostic techniques can be applied to any black-box model, including compressed LLMs. They work by perturbing inputs and observing changes in output to estimate feature importance. While computationally intensive for large models, they can be adapted for smaller, specialized models or for post-hoc analysis.
- Gradient-based Methods: Techniques like Integrated Gradients or Grad-CAM can highlight input features that strongly influence specific outputs by analyzing gradients. These methods are more computationally feasible for smaller models.
- Concept-based Explanations: Instead of just highlighting words, these methods aim to explain model behavior in terms of higher-level human-understandable concepts. This is an active research area.
- Challenges: The process of quantization, pruning, and distillation can sometimes obscure the internal workings of a model, making traditional XAI techniques harder to apply or interpret. Developing XAI methods specifically designed for these optimized architectures is a key research challenge.
Practical Applications and Use Cases
The ability to deploy efficient and explainable LLMs on the edge unlocks a vast array of transformative applications:
-
On-Device Assistants and Smart Devices: Imagine smartphones, smart speakers, or wearables performing complex language tasks (summarization, translation, personalized content generation, code completion) entirely offline. This enhances privacy, responsiveness, and functionality in areas with poor connectivity.
- Example: A smart doorbell that can summarize conversations at your door or identify specific speech patterns, all processed locally without sending audio to the cloud.
-
Industrial IoT and Edge Computing: In factories, oil rigs, or remote agricultural settings, LLMs can process sensor data, generate real-time reports, perform anomaly detection, or provide operational insights without relying on a central cloud.
- Example: An industrial robot that can understand natural language commands and explain its actions or potential failures to a technician on the factory floor.
-
Healthcare: Localized processing of patient notes, medical transcription, diagnostic support, and personalized health recommendations can be done directly on hospital servers or even patient devices, ensuring stringent data privacy and compliance with regulations like HIPAA.
- Example: An on-device LLM assisting doctors with summarizing medical literature or drafting patient reports, with all sensitive data remaining within the hospital's secure network.
-
Customer Service and Chatbots: Deploying specialized, domain-specific chatbots directly on customer devices or local servers for enhanced privacy, responsiveness, and cost-effectiveness. This is particularly valuable for businesses handling sensitive customer information.
- Example: A banking app with an integrated LLM chatbot that can answer complex financial queries or process transactions, with all interactions remaining on the user's device or the bank's secure local servers.
-
Autonomous Vehicles and Robotics: Real-time understanding of environmental cues, natural language interaction with passengers, and on-the-fly decision-making require ultra-low latency and robust offline capabilities.
- Example: An autonomous car that can understand nuanced voice commands from passengers ("Take the scenic route," "Find a charging station quickly") and explain its navigation choices in real-time.
-
Defense and Security: Processing intelligence, performing real-time threat analysis, and secure communication in air-gapped or battlefield environments where cloud connectivity is impossible or undesirable.
- Example: A field operative using a ruggedized device with an on-board LLM to quickly summarize intelligence reports or translate foreign language documents in a secure, offline manner.
-
Accessibility: Providing advanced language features (e.g., real-time speech-to-text, sign language translation, complex text simplification) directly on accessible devices, empowering individuals with disabilities without requiring constant internet access or compromising privacy.
The Road Ahead: Challenges and Opportunities
While significant progress has been made, several key challenges remain:
- Performance vs. Efficiency Trade-offs: The eternal dilemma. How much can we compress or shrink a model before its performance drops below acceptable thresholds for specific tasks? This often requires task-specific optimization.
- Generalization of SLMs: Can small models, often trained on highly curated but smaller datasets, generalize as effectively as their larger counterparts on diverse, unseen data?
- Unified Frameworks: Developing standardized frameworks and tools that seamlessly integrate various compression, PEFT, and XAI techniques across different hardware platforms.
- Continual Learning and Adaptation: How can efficient LLMs be continually updated and adapted on-device or at the edge with new information without requiring full retraining or significant resource consumption?
- Multi-modal Efficiency: Extending these efficiency and explainability techniques to multi-modal models (text + image, text + audio) for edge deployment, which introduces even greater complexity.
Conclusion
The drive towards efficient and explainable LLMs for edge/on-device deployment and specialized applications is not merely an optimization problem; it represents a fundamental paradigm shift in how we conceive, develop, and deploy AI. It promises to unlock new applications, enhance privacy and security, drastically reduce operational costs, and democratize access to advanced AI capabilities for a wider range of developers, organizations, and individuals.
For AI practitioners and enthusiasts, mastering these techniques – from quantization and LoRA to understanding the nuances of SLM architectures and the principles of XAI – will be an indispensable skill. The future of AI is not just about building bigger models, but about building smarter, more accessible, and more responsible ones that can thrive in the diverse, resource-constrained environments of the real world. This frontier is ripe with innovation, offering immense opportunities to shape the next generation of intelligent systems.