Retrieval-Augmented Generation (RAG): Grounding LLMs for Enterprise Accuracy
Explore how Retrieval-Augmented Generation (RAG) addresses the limitations of Large Language Models (LLMs), such as hallucinations and knowledge cutoffs, by grounding responses in verifiable, external data. Discover RAG's pivotal role in enhancing accuracy and reliability for enterprise applications.
The era of Large Language Models (LLMs) has ushered in unprecedented capabilities for generating human-like text, answering complex questions, and even writing code. Yet, as powerful as models like GPT-4, Claude, and Llama 3 are, they come with inherent limitations: the dreaded "hallucinations," knowledge cutoffs, and a tendency towards generic responses. For enterprises and specialized domains where accuracy, verifiability, and up-to-dateness are paramount, these limitations pose significant hurdles. This is where Retrieval-Augmented Generation (RAG) steps in, offering a pragmatic and powerful solution that marries the generative prowess of LLMs with the precision of information retrieval.
RAG is not just a buzzword; it's a rapidly evolving paradigm shift in how we leverage LLMs for real-world applications. It addresses the core challenges of LLM reliability by grounding their responses in verifiable, external knowledge, making them indispensable for critical tasks ranging from internal knowledge management to specialized scientific research.
The LLM Dilemma: Power vs. Precision
Before diving into RAG, let's briefly recap why it's so crucial. LLMs are trained on vast datasets, learning patterns, grammar, and facts. However, this training process imbues them with certain characteristics that can be problematic:
- Hallucinations: LLMs can confidently generate information that is factually incorrect, nonsensical, or entirely made up. This is a major trust issue, especially in domains like healthcare, finance, or legal.
- Knowledge Cutoff: Their knowledge is static, frozen at the point their training data was collected. They cannot access real-time information or proprietary internal documents.
- Lack of Specificity: While great at general knowledge, LLMs often struggle with highly specific, niche, or domain-specific queries without additional context.
- Explainability and Trust: Without knowing the source of an LLM's answer, it's difficult to verify its accuracy or understand its reasoning, hindering adoption in regulated industries.
- Cost and Complexity of Fine-tuning: While fine-tuning can inject new knowledge, it's expensive, time-consuming, and not always the most efficient way to update an LLM's knowledge base, especially for rapidly changing information.
RAG directly confronts these issues by introducing an external, dynamic, and verifiable knowledge source into the LLM's generation process.
Understanding the Core Mechanism of RAG
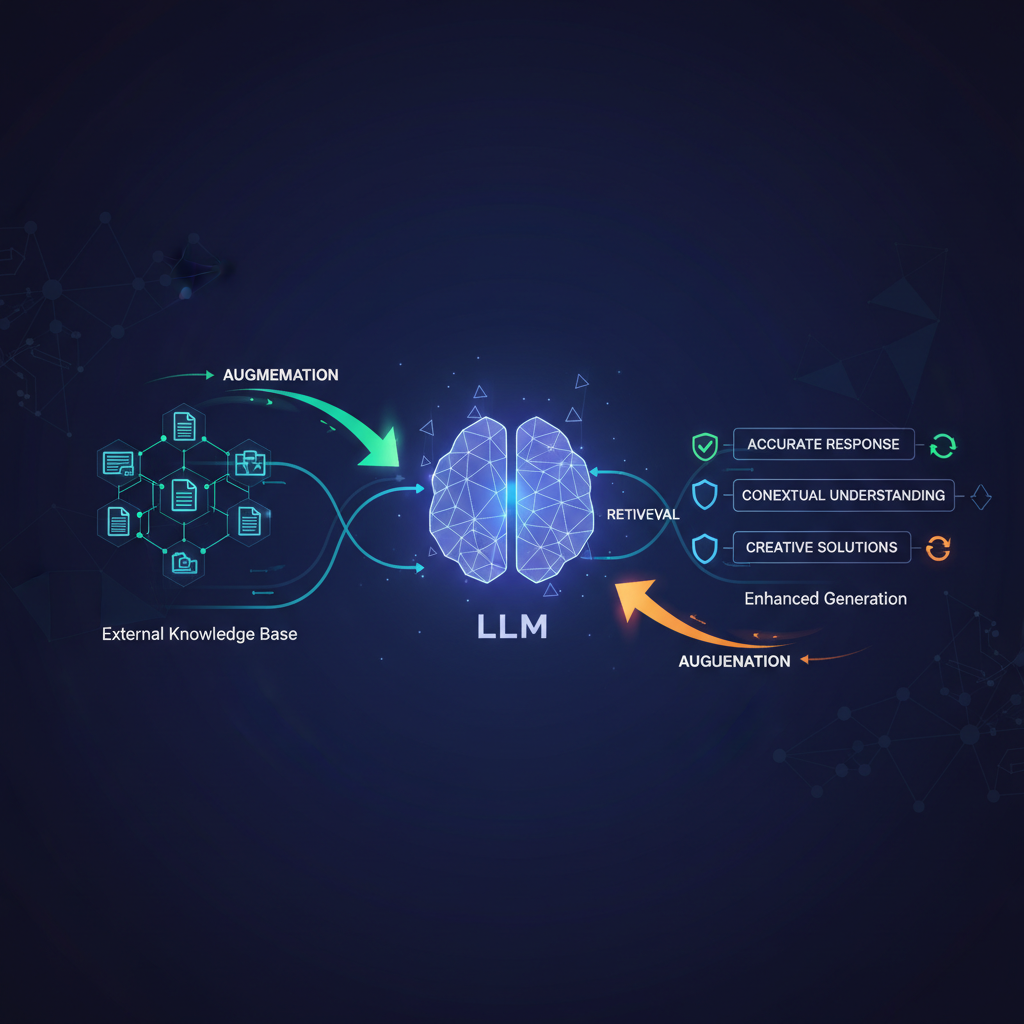
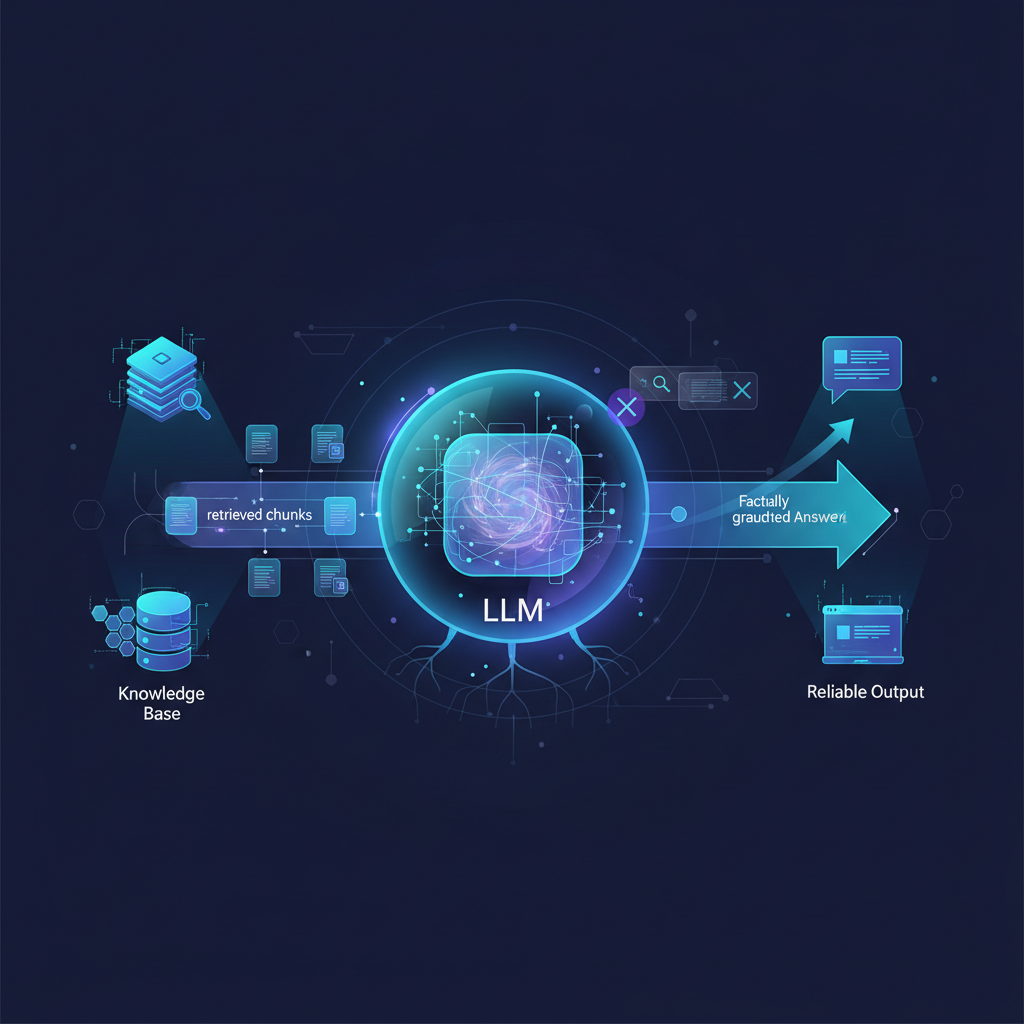
At its heart, RAG operates on a simple yet profound principle: don't just generate, first retrieve. When a user poses a query, a RAG system doesn't immediately hand it over to the LLM. Instead, it first searches a dedicated knowledge base for relevant information. This retrieved information then acts as a supplementary context for the LLM, guiding its generation to be accurate and grounded.
Imagine you're asking a question about your company's latest HR policy. Without RAG, an LLM might give a generic answer based on common HR practices. With RAG, the system first finds the exact policy document, extracts relevant sections, and then presents these sections to the LLM, instructing it to answer only based on the provided text.
The RAG workflow typically involves two main phases:
- Retrieval Phase (The "R"): Given a user query, the system identifies and fetches the most relevant pieces of information from an external knowledge base.
- Generation Phase (The "G"): The retrieved information, along with the original query, is then fed into an LLM as context. The LLM uses this context to formulate a coherent, accurate, and grounded response.
Diving Deep: Key Components and Recent Advancements
The elegance of RAG lies in its modularity. Each component can be optimized and swapped out independently, leading to a dynamic and rapidly evolving ecosystem of tools and techniques.
1. The Retrieval Phase: Finding the Needle in the Haystack
The quality of the retrieved information directly impacts the quality of the generated answer. This phase is critical and involves several sophisticated steps:
-
Knowledge Base Preparation:
- Document Ingestion: This involves collecting all relevant documents (PDFs, web pages, databases, internal wikis, etc.) that form your knowledge base.
- Chunking Strategies: Large documents are too big to fit into an LLM's context window and can dilute relevance. They must be broken down into smaller, semantically meaningful "chunks." Advanced chunking goes beyond fixed character limits, considering document structure (headings, paragraphs, tables), semantic boundaries, and even relationships between chunks. For instance, a chunk might include its parent heading to provide better context.
- Metadata Enrichment: Attaching metadata (e.g., author, date, source URL, document type) to chunks can significantly improve retrieval by allowing for filtered searches or boosting relevance.
-
Embedding Models:
- Once chunked, each piece of information (and the user's query) is converted into a numerical vector, called an "embedding." These embeddings capture the semantic meaning of the text.
- The choice of embedding model is crucial. Models like OpenAI's
text-embedding-3-large, Cohere'sembed-english-v3.0, or open-source alternatives likebge-large-en-v1.5are designed to produce high-quality, semantically rich embeddings. Specialized embeddings can also be trained for highly niche domains. The better the embeddings, the more accurately the system can find semantically similar chunks to the query.
-
Vector Databases (Vector Stores):
- These specialized databases (e.g., Pinecone, Weaviate, ChromaDB, Qdrant, Milvus) are optimized for storing and performing rapid similarity searches on high-dimensional vectors. When a query's embedding is generated, the vector database quickly finds the most similar document chunks based on vector distance (e.g., cosine similarity).
- Hybrid Search: A significant advancement is combining vector search (semantic similarity) with traditional keyword search (like BM25). This "hybrid search" captures both the meaning and the exact terms, often leading to more precise retrieval, especially for queries that contain specific keywords or product codes.
- Filtering Capabilities: Modern vector stores allow filtering results based on metadata, enabling more targeted retrieval (e.g., "find documents about X published in 2023 by author Y").
-
Re-ranking:
- Initial retrieval might return a broad set of potentially relevant documents. A "re-ranker" model (often a smaller, more powerful cross-encoder model) takes the top-N retrieved documents and the original query, and re-orders them based on their true relevance. This step significantly boosts the precision of the retrieved context, ensuring the LLM receives the most pertinent information.
-
Graph-based Retrieval:
- For highly structured or relational knowledge, integrating knowledge graphs can be transformative. Instead of just retrieving text chunks, RAG can query a knowledge graph to retrieve structured facts, relationships, and entities, providing a richer and more precise context to the LLM. This is particularly useful for answering complex, multi-hop questions.
2. The Generation Phase: Crafting the Answer
With the most relevant context in hand, the LLM takes over.
-
Prompt Engineering for Context: This is where the art of instructing the LLM comes in. The prompt must clearly tell the LLM to:
- Answer the user's question.
- Base its answer only on the provided context.
- Cite its sources (if desired).
- Avoid making up information if the context doesn't contain the answer.
- Example prompt structure:
You are an expert assistant. Answer the user's question based *only* on the provided context. If the answer is not found in the context, state that you don't have enough information. Do not make up any information. Context: [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] ... Question: [User's Query] Answer:You are an expert assistant. Answer the user's question based *only* on the provided context. If the answer is not found in the context, state that you don't have enough information. Do not make up any information. Context: [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] ... Question: [User's Query] Answer: - Chain-of-Thought (CoT) or Self-Reflection: For complex queries, prompts can guide the LLM to "think step-by-step" over the retrieved data, improving reasoning and accuracy.
-
Context Window Management: LLMs have a finite context window (the maximum number of tokens they can process at once). Efficiently managing this is crucial. Techniques include:
- Summarization: Summarizing lengthy retrieved documents before passing them to the LLM.
- Passage Selection: Intelligently selecting only the most critical sentences or paragraphs from the retrieved chunks.
- Adaptive Context: Dynamically adjusting the amount of retrieved context based on the query's complexity or the LLM's capacity.
-
Fine-tuning the Generator (Advanced RAG): While RAG aims to reduce the need for full LLM fine-tuning, some advanced setups might fine-tune the LLM specifically on how to use retrieved documents more effectively, or on generating answers in a specific format (e.g., always including citations in a particular style). This is often called "RAG-aware fine-tuning."
Evaluation and Optimization: Ensuring Quality and Trust
Deploying a RAG system requires continuous evaluation and optimization to ensure it performs as expected.
-
RAG-specific Metrics: Traditional NLP metrics (like BLEU or ROUGE) are insufficient for RAG. New metrics focus on:
- Context Relevance: How pertinent are the retrieved documents to the query?
- Faithfulness (or Groundedness): Does the generated answer solely rely on information present in the retrieved context? This is key to preventing hallucinations.
- Answer Relevance: How well does the final answer address the user's original query?
- Answer Correctness: Is the answer factually accurate based on the source documents?
- Latency and Cost: Practical considerations for production systems.
-
A/B Testing and Human-in-the-Loop: Iterative improvement is essential. A/B testing different retrieval strategies or prompt variations can reveal optimal configurations. Human reviewers are invaluable for assessing answer quality, faithfulness, and identifying edge cases that automated metrics might miss.
Emerging Trends in RAG
The RAG landscape is evolving rapidly, pushing the boundaries of what's possible:
- Multi-modal RAG: Extending RAG beyond text to retrieve and generate answers from images, audio, or video. Imagine querying a product manual and getting an answer that includes relevant diagrams or video tutorials. This relies on multi-modal embedding models.
- Adaptive RAG (or Self-RAG): Systems that dynamically decide when and how to retrieve information. An LLM might first attempt to answer a question from its internal knowledge, and only if it's uncertain or needs more detail, trigger a retrieval step. This optimizes for latency and cost.
- Self-Correction and Self-Reflection in RAG: LLMs are increasingly being designed to evaluate their own generated answers against the retrieved context. If discrepancies are found, they can iteratively refine their response or even re-initiate retrieval with a modified query.
- Agentic RAG: Integrating RAG into autonomous AI agents. These agents can plan complex tasks, use RAG as a tool to gather information, execute other tools (e.g., API calls), and reflect on their actions, leading to more robust and capable systems.
- RAG for Code Generation: Using RAG to retrieve relevant code snippets, API documentation, or best practices to improve the accuracy, efficiency, and security of LLM-generated code.
- Long-Context RAG: While context windows are growing, RAG remains crucial for truly massive knowledge bases. New techniques are emerging to handle extremely long retrieved contexts more efficiently, perhaps by hierarchical summarization or selective attention mechanisms.
Practical Applications for AI Practitioners
RAG is not just theoretical; it's a powerful enabler for a multitude of real-world applications across industries:
-
Building Custom Chatbots and Virtual Assistants:
- Internal Knowledge Bases: Empower employees with instant, accurate answers about company policies, HR benefits, IT troubleshooting, or internal project documentation. "What's the policy on remote work?" or "How do I reset my VPN?"
- Customer Support: Provide customers with precise, up-to-date information on products, services, FAQs, and troubleshooting guides, reducing reliance on human agents for common queries. "How do I connect my new device?" or "What's your return policy?"
-
Enhanced Search Engines:
- Move beyond traditional keyword search to semantic search that understands the intent behind queries. Instead of just listing documents, provide synthesized answers directly from the content, citing sources. This is particularly valuable for complex document repositories.
-
Automated Research Assistants:
- Legal: Quickly summarize case law, contracts, or regulatory documents, identifying key precedents or clauses.
- Medical/Scientific: Accelerate literature reviews, extract insights from research papers, or answer specific questions from vast medical databases. "What are the latest clinical trials for drug X?"
- Financial: Analyze financial reports, market research, or economic forecasts to provide summarized, sourced insights for analysts.
-
Content Creation & Curation:
- Generate drafts of articles, reports, marketing copy, or technical documentation that are grounded in specific source materials, ensuring factual accuracy and consistency. "Draft a blog post about our new product feature, referencing the technical specification document."
-
Data Analysis & Reporting:
- Query complex, structured, or unstructured datasets (e.g., sensor logs, customer feedback, internal databases) in natural language and receive summarized, sourced insights, making data more accessible to non-technical users. "What were the sales trends for product Y in Q3, and what factors influenced them according to the market reports?"
-
Personalized Learning and Education:
- Create adaptive learning platforms that can answer student questions based on specific course materials, textbooks, or supplementary readings, providing explanations tailored to the context.
Conclusion
Retrieval-Augmented Generation stands as a testament to the power of hybrid AI approaches. By intelligently combining the vast generative capabilities of LLMs with the verifiable precision of information retrieval systems, RAG offers a robust framework for building intelligent applications that are not only powerful but also trustworthy, accurate, and up-to-date.
For AI practitioners, understanding and implementing RAG is no longer optional; it's a critical skill. The rapid evolution of open-source tools, vector databases, and advanced retrieval techniques makes this field incredibly dynamic and ripe for innovation. As we push the boundaries of what LLMs can do, RAG ensures that these powerful models remain grounded in reality, making them truly indispensable for enterprise solutions and specialized domains where accuracy and reliability are paramount. The future of practical, responsible AI deployment is undeniably retrieval-augmented.