Unlocking LLM Potential: A Deep Dive into Retrieval-Augmented Generation (RAG)
Explore Retrieval-Augmented Generation (RAG) systems, a powerful solution addressing Large Language Models' (LLMs) limitations like hallucination and outdated knowledge. Learn how RAG combines LLM creativity with factual grounding from external sources, making it key for reliable AI applications.
Unlocking the Full Potential of LLMs: A Deep Dive into Retrieval-Augmented Generation (RAG) Systems
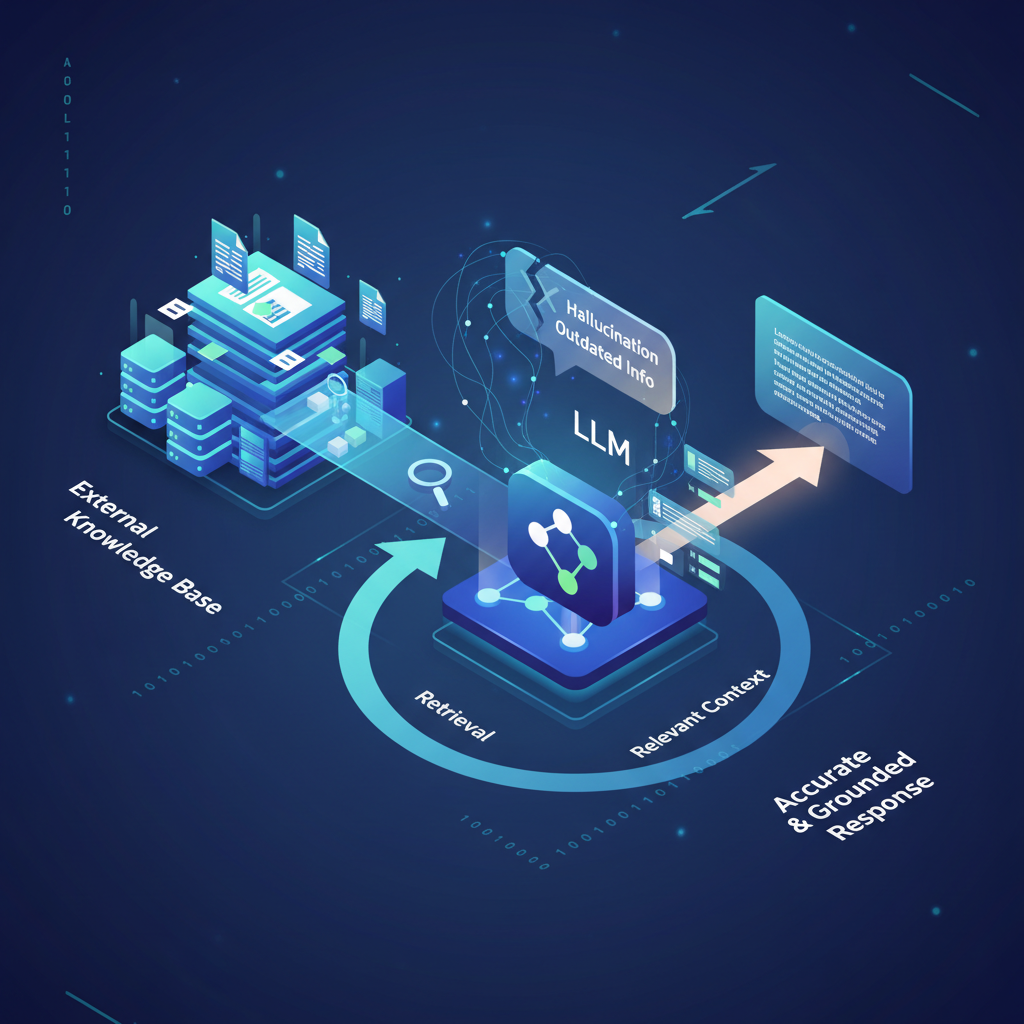
Large Language Models (LLMs) have revolutionized how we interact with information, generating human-like text with astonishing fluency and creativity. From drafting emails to writing code, their capabilities seem boundless. Yet, beneath this impressive facade lie inherent limitations: LLMs can "hallucinate" facts, their knowledge is frozen at their training data cutoff, and they often struggle with domain-specific or proprietary information. This is where Retrieval-Augmented Generation (RAG) systems step in, offering a powerful paradigm shift that marries the generative prowess of LLMs with the factual grounding of external knowledge.
RAG is rapidly becoming the cornerstone for building reliable, enterprise-grade LLM applications. It addresses the core challenges of LLMs by enabling them to access, process, and synthesize information from up-to-date, verifiable sources. For AI practitioners and enthusiasts alike, understanding RAG isn't just an advantage; it's a necessity for building the next generation of intelligent systems.
The Core Problem: Why Pure LLMs Fall Short
Before diving into RAG, let's briefly recap the inherent challenges of standalone LLMs:
- Hallucinations: LLMs, despite their vast training data, can confidently generate factually incorrect or nonsensical information. This isn't malicious; it's a byproduct of their probabilistic nature, where they predict the most plausible next word based on patterns, not necessarily truth.
- Outdated Knowledge: An LLM's knowledge is a snapshot of its training data. If that data was collected in 2023, it won't know about events or developments from 2024. Fine-tuning for updates is costly and time-consuming.
- Lack of Transparency and Explainability: When an LLM provides an answer, it's often unclear why it gave that specific response or where it got the information. This "black box" nature hinders trust and adoption in critical applications.
- Domain Specificity: LLMs are generalists. They lack deep, specialized knowledge required for niche fields like proprietary company policies, specific legal precedents, or highly technical medical guidelines. Fine-tuning can help, but it's resource-intensive and still prone to the issues above.
- Cost of Fine-tuning: While powerful, fine-tuning an LLM for specific tasks or knowledge domains requires significant computational resources, expertise, and a large, high-quality dataset, making it inaccessible for many organizations.
RAG directly confronts these limitations by providing LLMs with a dynamic, verifiable external memory.
What is Retrieval-Augmented Generation (RAG)?
At its heart, RAG is a framework that enhances the capabilities of LLMs by enabling them to retrieve relevant information from an external knowledge base before generating a response. Instead of relying solely on its internal, static knowledge, the LLM is given specific, up-to-date context to inform its output.
The typical RAG workflow involves two primary phases:
- Retrieval: When a user poses a query, the system first searches a curated knowledge base (e.g., documents, databases, web pages) for information relevant to that query. This usually involves converting the query and the documents into numerical representations called "embeddings" and then finding documents whose embeddings are semantically similar to the query's embedding.
- Augmentation & Generation: The retrieved relevant documents (or snippets thereof) are then passed as additional context to the LLM along with the original user query. The LLM then uses this augmented prompt to generate a more accurate, grounded, and contextually relevant response.
This process ensures that the LLM's output is not only coherent and fluent but also factually accurate and traceable to its source.
The RAG Architecture: A Deeper Dive
Let's break down the components and processes involved in a typical RAG system.
1. Data Ingestion and Indexing
This is the foundational step where your external knowledge base is prepared for retrieval.
- Data Sources: This can be anything from internal company documents (PDFs, Word files, Confluence pages), databases, websites, scientific papers, or even structured data.
- Document Loading: The raw data needs to be loaded into the system. Frameworks like LangChain and LlamaIndex provide numerous document loaders for various file types and data sources.
- Chunking: Large documents are broken down into smaller, manageable "chunks" or segments. This is crucial because LLMs have context window limits, and smaller chunks improve retrieval precision.
- Simple Chunking: Fixed-size chunks (e.g., 500 characters with 50-character overlap).
- Semantic Chunking: A more advanced approach where chunks are created based on semantic coherence. This might involve using an LLM to identify logical sections or using NLP techniques to detect topic shifts. For example, a paragraph on "LLM limitations" should ideally be a single chunk, even if it spans more characters than a fixed-size chunk.
- Hierarchical Chunking: Creating chunks at multiple granularities (e.g., summaries of documents, then detailed sections, then individual paragraphs). This allows for multi-level retrieval, where a high-level query might retrieve a summary, and a detailed follow-up might retrieve specific paragraphs.
- Embedding Generation: Each chunk is converted into a high-dimensional vector (an embedding) using an embedding model. These embeddings capture the semantic meaning of the text. Documents with similar meanings will have embeddings that are close to each other in the vector space.
- Example Embedding Models: OpenAI Embeddings, Cohere Embeddings, various
sentence-transformersmodels from Hugging Face, Google'stext-embedding-gecko.
- Example Embedding Models: OpenAI Embeddings, Cohere Embeddings, various
- Vector Database (Vector Store): The generated embeddings, along with their corresponding original text chunks, are stored in a specialized database optimized for vector similarity search.
- Key Technologies: Pinecone, Weaviate, Qdrant, Chroma, Milvus, Faiss. These databases allow for efficient nearest-neighbor searches, quickly finding chunks whose embeddings are closest to a given query embedding.
2. Retrieval Phase
When a user submits a query:
- Query Embedding: The user's query is also converted into an embedding using the same embedding model used for the documents.
- Similarity Search: The query embedding is used to perform a similarity search in the vector database. The database returns the top-k most semantically similar document chunks.
- Hybrid Search (RAG-Fusion): To overcome the limitations of pure semantic search (which might miss keyword matches or struggle with very specific entity names), hybrid search combines:
- Vector Search (Semantic): Using embeddings for conceptual similarity.
- Keyword Search (Lexical): Using traditional search algorithms like BM25 or TF-IDF for exact or partial keyword matches.
- The results from both methods are often combined and re-ranked to achieve better recall and precision. For instance, reciprocal rank fusion (RRF) is a common technique to merge and re-rank results from different search methods.
3. Augmentation and Generation Phase
The retrieved chunks are then used to augment the LLM's prompt.
- Prompt Construction: The original user query and the retrieved relevant document chunks are combined into a single, comprehensive prompt for the LLM.
- Example Prompt Structure:
"You are an AI assistant. Use the following context to answer the user's question. If the answer is not in the context, state that you don't know. Context: [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] [Retrieved Document Chunk 3] ... Question: [User's Original Query]""You are an AI assistant. Use the following context to answer the user's question. If the answer is not in the context, state that you don't know. Context: [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] [Retrieved Document Chunk 3] ... Question: [User's Original Query]"
- Example Prompt Structure:
- LLM Inference: The augmented prompt is sent to the chosen LLM (e.g., GPT-4, Claude, Llama 3). The LLM processes this information and generates a response that is grounded in the provided context.
- Response Generation: The LLM synthesizes information from the retrieved chunks and its own general knowledge to formulate a coherent, accurate, and relevant answer.
Advanced RAG Architectures and Emerging Trends
The RAG landscape is evolving rapidly, with researchers and practitioners developing increasingly sophisticated techniques to enhance performance, reliability, and efficiency.
1. Advanced Retrieval Strategies
- Self-RAG: Instead of a simple retrieval-then-generate pipeline, Self-RAG introduces an LLM-driven self-reflection mechanism. The LLM learns to critique its own retrieved documents, decide if more retrieval is needed, and adapt its generation strategy. It can generate "critique tokens" to assess document quality and relevance, improving both retrieval and generation.
- Corrective RAG (CRAG): CRAG introduces a "retrieval evaluator" that assesses the quality of the initial retrieved documents. If the quality is low, it can trigger a re-retrieval process (e.g., by reformulating the query, expanding the search scope) or adjust the generation strategy (e.g., by relying more on the LLM's parametric knowledge if retrieval is poor).
- Multi-hop RAG: For complex questions requiring synthesis from multiple, disparate pieces of information, multi-hop RAG performs several retrieval steps. It might retrieve an initial set of documents, extract sub-questions or entities, and then perform subsequent retrievals based on these to build a comprehensive answer.
- Graph-based RAG: Integrating knowledge graphs with vector databases. Knowledge graphs provide structured relationships between entities, which can be invaluable for complex queries. For example, if a query asks "Who manages project X?", a graph can directly link "project X" to its "manager" entity, while vector search might only retrieve documents mentioning both. This combination provides both semantic breadth and structural precision.
2. Optimized Chunking and Indexing
- Parent Document Retrieval: Instead of retrieving only small chunks, this strategy retrieves a small, semantically relevant chunk, but then uses its "parent" (a larger surrounding chunk or the full document) as context for the LLM. This balances retrieval precision with providing sufficient context.
- Small-to-Large Chunking: Embed small, precise chunks for retrieval, but then retrieve the larger, original chunk (or even the full document) for the LLM to process. This ensures the LLM gets ample context while the retrieval remains highly targeted.
- Sentence Window Retrieval: Similar to small-to-large, but uses individual sentences for embedding and retrieval, then expands to a "window" of surrounding sentences for the LLM context.
- Metadata Filtering: Storing metadata (author, date, document type, source) alongside embeddings allows for pre-filtering retrieval results, ensuring only documents meeting specific criteria are considered.
3. Contextual Compression and Re-ranking
Even after initial retrieval, the list of documents might contain redundancy or less relevant information.
- LLM-based Re-ranking: An LLM can be used to re-rank the initially retrieved documents based on their relevance to the query. This often involves feeding the query and each retrieved document to the LLM and asking it to score or rank them. This is more computationally intensive but can significantly improve the quality of the context passed to the final generation LLM.
- Embedding-based Re-ranking: More sophisticated embedding models or cross-encoders can be used to re-score the relevance of retrieved documents.
- Contextual Compression: Techniques to summarize or extract only the most pertinent information from the retrieved documents, ensuring the LLM receives a concise and high-quality context within its token limit.
4. Agentic RAG
This is a powerful emerging trend where RAG is integrated into autonomous AI agents. An agent doesn't just answer a query; it plans, executes, and reflects. In an agentic RAG system, the agent decides:
- When to retrieve: Is external knowledge needed for this part of the task?
- What to retrieve: Formulating specific search queries.
- How to use retrieved information: Synthesizing it, refining it, or using it to inform further actions.
- Tool Use: RAG becomes one tool among many (e.g., code interpreter, API calls) that an agent can leverage to achieve complex goals.
5. Multimodal RAG
Extending RAG beyond text to incorporate other data types like images, audio, and video. Imagine an LLM answering questions about a product based on its user manual (text), product images (visuals), and a video tutorial (audio/video). This requires multimodal embedding models and specialized vector stores.
Practical Applications and Value for AI Practitioners
RAG is not just a theoretical concept; it's a practical powerhouse for real-world AI applications.
-
Enterprise Search and Knowledge Management:
- Use Case: An employee needs to find a specific company policy on remote work expenses or detailed technical specifications for an internal product.
- RAG Value: RAG-powered chatbots can sift through thousands of internal documents, PDFs, Confluence pages, and HR policies to provide precise, up-to-date answers, reducing search time and improving employee productivity. It prevents the LLM from "making up" policies.
-
Customer Support and Chatbots:
- Use Case: A customer asks about troubleshooting steps for a new product, warranty details, or specific features.
- RAG Value: Chatbots can access the latest product manuals, FAQs, and support documentation. This ensures accurate, consistent answers, reduces agent workload, and prevents the chatbot from providing incorrect information that could frustrate customers or lead to returns.
-
Legal and Medical Research:
- Use Case: A lawyer needs to find precedents for a specific case, or a doctor requires the latest research on a rare disease or drug interaction.
- RAG Value: Professionals can quickly query vast databases of legal documents, medical journals, and patient records. RAG ensures the LLM provides grounded summaries and citations, critical for fields where accuracy and source verification are paramount.
-
Educational Tools:
- Use Case: A student asks a question about a specific concept covered in their textbook or lecture notes.
- RAG Value: Personalized learning assistants can provide explanations and answer questions strictly based on the course material, preventing the LLM from introducing irrelevant or off-topic information. It can even cite page numbers or lecture segments.
-
Content Generation and Summarization:
- Use Case: Generating reports, articles, or summaries that must be factually accurate and grounded in specific source documents (e.g., financial reports, scientific studies).
- RAG Value: Instead of relying on general LLM knowledge, RAG ensures generated content adheres to the provided sources, reducing the need for extensive fact-checking and improving trustworthiness.
-
Data Analysis and Reporting:
- Use Case: An analyst wants to ask natural language questions about data stored in various structured (databases) and unstructured (reports, emails) formats.
- RAG Value: RAG can enable LLMs to query databases (via SQL generation), synthesize insights from reports, and generate comprehensive summaries or dashboards, making data more accessible to non-technical users.
Key Technologies and Tools
Building RAG systems involves a stack of specialized tools:
- Vector Databases:
- Pinecone: Managed vector database, highly scalable.
- Weaviate: Open-source, supports various data types, GraphQL API.
- Qdrant: Open-source, high-performance, written in Rust.
- Chroma: Lightweight, open-source, often used for local development and smaller-scale RAG.
- Milvus: Open-source, cloud-native vector database.
- Faiss: Facebook AI Similarity Search, a library for efficient similarity search, often used as a local index.
- Embedding Models:
- OpenAI Embeddings: High-quality, widely used, proprietary.
- Cohere Embeddings: Offers various models, good performance, proprietary.
- Hugging Face
sentence-transformers: A vast collection of open-source models for generating sentence, paragraph, and image embeddings. - Google's
text-embedding-gecko(part of Vertex AI): Google's proprietary embedding models.
- Orchestration Frameworks:
- LangChain: A popular framework for developing LLM applications, providing abstractions for chains, agents, document loaders, vector stores, and more. Simplifies building complex RAG workflows.
- LlamaIndex: Another powerful framework specifically designed for building LLM applications over custom data, with a strong focus on data indexing and retrieval strategies.
- Large Language Models (LLMs):
- GPT-3.5/4 (OpenAI): Leading proprietary models, highly capable.
- Claude (Anthropic): Another strong proprietary contender, known for its long context window and safety features.
- Llama 2/3 (Meta): Powerful open-source models, suitable for self-hosting and fine-tuning.
- Mistral (Mistral AI): High-performance, efficient open-source models.
- Evaluation Tools:
- Ragas: An open-source framework specifically designed to evaluate RAG pipelines, measuring metrics like faithfulness, answer relevance, context precision, and recall.
- TruLens: Provides observability and evaluation for LLM applications, including RAG.
Building a Simple RAG System (Conceptual Code Example)
Let's illustrate the basic flow with a conceptual Python example using LangChain and Chroma.
# 1. Install necessary libraries
# pip install langchain langchain-community langchain-openai chromadb pypdf
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# --- 1. Data Ingestion and Indexing ---
# Load documents (e.g., a PDF file)
# For this example, let's assume 'example.pdf' exists in the same directory
# You would replace this with your actual data loading logic
try:
loader = PyPDFLoader("example.pdf")
documents = loader.load()
except FileNotFoundError:
print("example.pdf not found. Creating a dummy document for demonstration.")
from langchain.docstore.document import Document
documents = [Document(page_content="""
The quick brown fox jumps over the lazy dog. This is a very important
document about foxes and dogs. Foxes are known for their cunning,
while dogs are loyal companions. The average lifespan of a fox is 2-5 years,
and they typically weigh between 6-10 kg. Dogs, on the other hand,
have a much wider range of lifespans and weights depending on the breed.
For instance, a Chihuahua might live 15 years and weigh 2 kg,
while a Great Dane might live 7 years and weigh 70 kg.
This document also covers various aspects of animal behavior,
including hunting strategies of foxes and the playful nature of dogs.
""")]
# Chunk documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)
print(f"Split {len(documents)} document(s) into {len(chunks)} chunks.")
# Generate embeddings and store in a vector database
embeddings = OpenAIEmbeddings(model="text-embedding-3-small") # Using a smaller, cost-effective model
vectorstore = Chroma.from_documents(chunks, embeddings, persist_directory="./chroma_db")
print("Vector store created and persisted.")
# --- 2. Retrieval & Generation ---
# Initialize the LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.7)
# Create a retriever from the vector store
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # Retrieve top 3 relevant chunks
# Create the RAG chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 'stuff' combines all retrieved docs into one prompt
retriever=retriever,
return_source_documents=True # To see which documents were used
)
# User query
query = "What is the average lifespan of a fox and how does it compare to dogs?"
print(f"\nUser Query: {query}")
# Get response
result = qa_chain.invoke({"query": query})
print("\n--- RAG Response ---")
print(result["result"])
print("\n--- Sources Used ---")
for doc in result["source_documents"]:
print(f"- Content: {doc.page_content[:150]}...") # Print first 150 chars
print(f" Source: {doc.metadata.get('source', 'N/A')}, Page: {doc.metadata.get('page', 'N/A')}")
# Example of a query where the answer might not be in the context
query_no_context = "What is the capital of France?"
print(f"\nUser Query (No Context): {query_no_context}")
result_no_context = qa_chain.invoke({"query": query_no_context})
print("\n--- RAG Response (No Context) ---")
print(result_no_context["result"])
print("\n--- Sources Used (No Context) ---")
for doc in result_no_context["source_documents"]:
print(f"- Content: {doc.page_content[:150]}...")
print(f" Source: {doc.metadata.get('source', 'N/A')}, Page: {doc.metadata.get('page', 'N/A')}")
# Note: For 'stuff' chain type, if the answer isn't in the *retrieved context*,
# the LLM might still use its internal knowledge if not explicitly instructed
# to *only* use the context. For strict grounding, add "If the answer is not
# in the context, state that you don't know." to the prompt template.
# 1. Install necessary libraries
# pip install langchain langchain-community langchain-openai chromadb pypdf
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# --- 1. Data Ingestion and Indexing ---
# Load documents (e.g., a PDF file)
# For this example, let's assume 'example.pdf' exists in the same directory
# You would replace this with your actual data loading logic
try:
loader = PyPDFLoader("example.pdf")
documents = loader.load()
except FileNotFoundError:
print("example.pdf not found. Creating a dummy document for demonstration.")
from langchain.docstore.document import Document
documents = [Document(page_content="""
The quick brown fox jumps over the lazy dog. This is a very important
document about foxes and dogs. Foxes are known for their cunning,
while dogs are loyal companions. The average lifespan of a fox is 2-5 years,
and they typically weigh between 6-10 kg. Dogs, on the other hand,
have a much wider range of lifespans and weights depending on the breed.
For instance, a Chihuahua might live 15 years and weigh 2 kg,
while a Great Dane might live 7 years and weigh 70 kg.
This document also covers various aspects of animal behavior,
including hunting strategies of foxes and the playful nature of dogs.
""")]
# Chunk documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)
print(f"Split {len(documents)} document(s) into {len(chunks)} chunks.")
# Generate embeddings and store in a vector database
embeddings = OpenAIEmbeddings(model="text-embedding-3-small") # Using a smaller, cost-effective model
vectorstore = Chroma.from_documents(chunks, embeddings, persist_directory="./chroma_db")
print("Vector store created and persisted.")
# --- 2. Retrieval & Generation ---
# Initialize the LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.7)
# Create a retriever from the vector store
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # Retrieve top 3 relevant chunks
# Create the RAG chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 'stuff' combines all retrieved docs into one prompt
retriever=retriever,
return_source_documents=True # To see which documents were used
)
# User query
query = "What is the average lifespan of a fox and how does it compare to dogs?"
print(f"\nUser Query: {query}")
# Get response
result = qa_chain.invoke({"query": query})
print("\n--- RAG Response ---")
print(result["result"])
print("\n--- Sources Used ---")
for doc in result["source_documents"]:
print(f"- Content: {doc.page_content[:150]}...") # Print first 150 chars
print(f" Source: {doc.metadata.get('source', 'N/A')}, Page: {doc.metadata.get('page', 'N/A')}")
# Example of a query where the answer might not be in the context
query_no_context = "What is the capital of France?"
print(f"\nUser Query (No Context): {query_no_context}")
result_no_context = qa_chain.invoke({"query": query_no_context})
print("\n--- RAG Response (No Context) ---")
print(result_no_context["result"])
print("\n--- Sources Used (No Context) ---")
for doc in result_no_context["source_documents"]:
print(f"- Content: {doc.page_content[:150]}...")
print(f" Source: {doc.metadata.get('source', 'N/A')}, Page: {doc.metadata.get('page', 'N/A')}")
# Note: For 'stuff' chain type, if the answer isn't in the *retrieved context*,
# the LLM might still use its internal knowledge if not explicitly instructed
# to *only* use the context. For strict grounding, add "If the answer is not
# in the context, state that you don't know." to the prompt template.
This example demonstrates the fundamental steps: loading data, chunking, embedding, storing in a vector database, and then using that database to retrieve context for an LLM to answer questions. The return_source_documents=True is vital for transparency and debugging.
Conclusion
Retrieval-Augmented Generation represents a critical paradigm shift in how we build and deploy LLM applications. By marrying the generative power of LLMs with the factual grounding of external knowledge bases, RAG offers a robust solution to many of the current limitations of AI. It empowers LLMs to be more accurate, up-to-date, transparent, and trustworthy, making them suitable for a far wider range of sensitive and critical applications.
For AI practitioners, RAG is an indispensable tool for moving LLM projects from experimental prototypes to production-ready systems. For enthusiasts, it opens up a fascinating avenue to explore how AI can be made more reliable and explainable. The ongoing innovations in RAG architectures—from self-reflection and multi-hop reasoning to multimodal integration and agentic systems—promise even more powerful and reliable AI applications in the near future. Embracing RAG is not just about enhancing LLMs; it's about building a more responsible and impactful AI ecosystem.


