Unlocking LLM Potential: How Retrieval-Augmented Generation (RAG) Transforms Enterprise AI
Large Language Models offer incredible fluency but struggle with accuracy and up-to-date information. Discover how Retrieval-Augmented Generation (RAG) addresses these limitations, grounding LLM responses in verifiable data for reliable, context-aware enterprise AI applications.
Large Language Models (LLMs) have revolutionized the way we interact with information, generating human-like text with astonishing fluency. From creative writing to complex problem-solving, their capabilities seem boundless. However, beneath the surface of their impressive abilities lie inherent limitations: they can "hallucinate" facts, their knowledge is frozen at their last training cutoff, and they often struggle with domain-specific or proprietary information. For enterprises looking to leverage LLMs for critical applications, these limitations are not just inconveniences; they are showstoppers.
Enter Retrieval-Augmented Generation (RAG). RAG isn't just a clever trick; it's a fundamental architectural pattern that addresses these core LLM shortcomings head-on. By grounding LLM responses in external, verifiable, and up-to-date data, RAG transforms LLMs from impressive generalists into reliable, accurate, and context-aware specialists. This paradigm shift is making RAG the de facto standard for building enterprise-grade LLM applications, driving innovation across industries.
The Foundational Pillars of RAG: A Quick Refresher
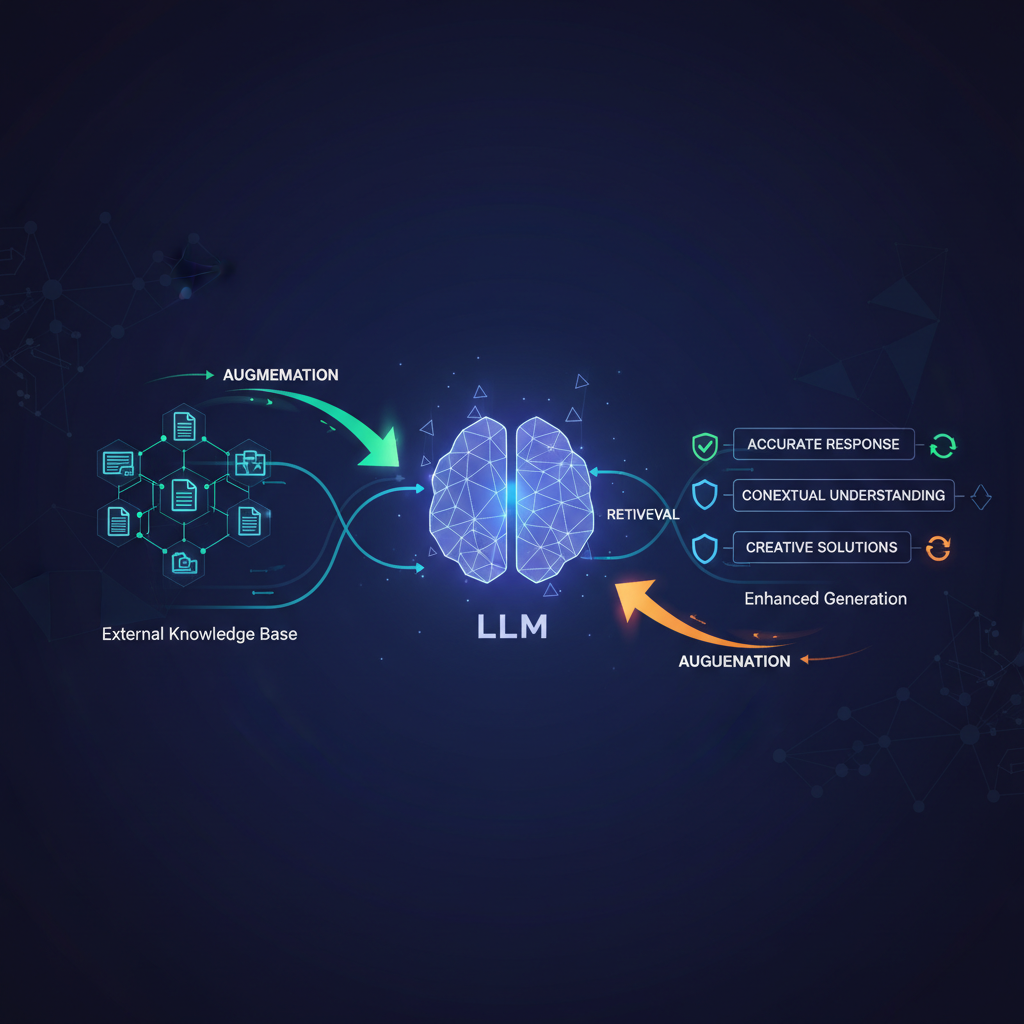
At its heart, RAG combines the strengths of information retrieval systems with the generative power of LLMs. The basic workflow involves three key steps:
-
Indexing (Preparation): Your proprietary data (documents, databases, internal wikis, etc.) is processed and stored in a searchable format. This typically involves:
- Chunking: Breaking down large documents into smaller, semantically coherent pieces (chunks). This is crucial because LLMs have token limits, and smaller chunks improve retrieval precision.
- Embedding: Converting these text chunks into numerical vector representations (embeddings) using an embedding model. These vectors capture the semantic meaning of the text.
- Vector Storage: Storing these embeddings in a specialized database known as a vector store (e.g., Pinecone, Weaviate, Qdrant, Chroma, Milvus). This allows for efficient similarity search.
-
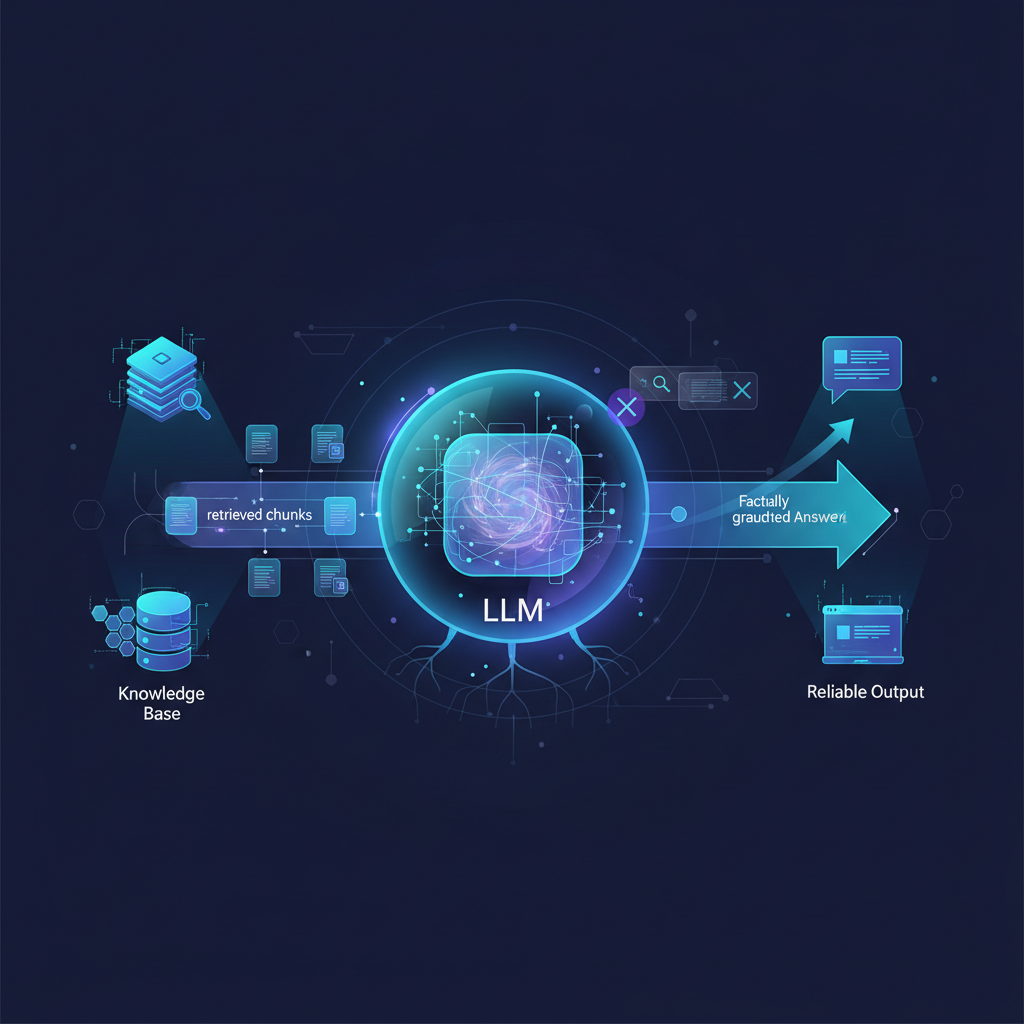
Retrieval: When a user poses a query, it's also converted into an embedding. This query embedding is then used to search the vector store for the most semantically similar data chunks. The goal is to find the most relevant pieces of information from your knowledge base that could help answer the query.
-
Generation: The retrieved chunks, along with the original user query, are then fed as context into the LLM. The LLM then synthesizes an answer, using its generative capabilities but strictly adhering to the provided context. This grounding prevents hallucinations and ensures the response is based on factual, verifiable information.
This elegant architecture allows LLMs to access and utilize knowledge far beyond their original training data, making them incredibly powerful for tasks requiring specific, current, or proprietary information.
Beyond the Basics: Advanced RAG Techniques for Enterprise Applications
While the foundational RAG architecture is powerful, the field is evolving at a breakneck pace. For enterprise-grade applications, simple vector search often isn't enough. Here, we delve into advanced techniques that significantly enhance RAG system performance, robustness, and reliability.
Advanced Retrieval Strategies: Finding the Needle in the Haystack
The quality of the LLM's answer is directly proportional to the quality of the retrieved context. Advanced retrieval focuses on making this step as precise and comprehensive as possible.
-
Hybrid Search: Pure vector search (dense retrieval) excels at semantic similarity but can sometimes miss exact keyword matches, especially for specific entities or codes. Conversely, traditional keyword search (sparse retrieval, e.g., BM25) is great for exact matches but struggles with synonyms or conceptual queries. Hybrid search combines both, running parallel searches and then merging or reranking results, offering the best of both worlds.
- Example: A query like "HR policy on remote work expenses" might benefit from keyword search for "HR policy" and vector search for "remote work expenses" to capture policy nuances.
-
Graph-based Retrieval: For highly interconnected data or scenarios requiring reasoning over relationships, knowledge graphs offer a powerful alternative. Instead of just retrieving text chunks, RAG can query a knowledge graph to retrieve structured facts, entities, and relationships. These structured facts can then be linearized and fed to the LLM.
- Example: An enterprise knowledge base about products might store information like "Product X is a component of System Y," "System Y is manufactured by Company Z," and "Company Z has a support contact email." A graph query can retrieve all these related facts to answer "Who manufactures System Y and how do I contact them for support?"
-
Sentence Window Retrieval / Small-to-Big Retrieval: A common challenge is that the optimal chunk size for embedding (small, focused for precision) is often different from the optimal context size for the LLM (larger, providing more surrounding detail). This technique addresses this by:
- Embedding and retrieving small, focused "sentence window" chunks.
- Once the top
ksmall chunks are identified, retrieving the larger, original document section (e.g., the full paragraph or even the whole page) from which those small chunks originated. This larger context is then passed to the LLM.
- Example: If a user asks about a specific regulation number, the small chunk might contain just the regulation. The larger context would provide the full regulatory text, allowing the LLM to explain it comprehensively.
-
Multi-vector Retrieval: Instead of representing a document with a single embedding, this approach creates multiple representations for different aspects of a document. For instance, a document might have embeddings for:
- Its full text.
- A concise summary.
- Key phrases or entities within it.
- A table of contents or section headers. When querying, the system can choose which embedding type to use for retrieval, or even combine results from multiple types.
- Example: A legal document might have a summary embedding for quick conceptual searches and full-text embeddings for detailed clause matching.
-
Agentic Retrieval: This represents a more dynamic and intelligent approach where an LLM acts as an "agent" to decide how to retrieve information. Instead of a fixed retrieval pipeline, the agent can:
- Break down complex queries into sub-queries.
- Perform multiple searches using different strategies or keywords.
- Refine its search based on initial retrieval results.
- Select appropriate tools (e.g., vector store, SQL database, web search API) for different parts of the query.
- Example: For "What are the Q3 sales figures for the European market, and how do they compare to Q2?", an agent might first query a SQL database for sales figures, then use a vector store to find market analysis reports, and finally synthesize the answer.
Query Transformation and Optimization: Asking the Right Questions
Sometimes, the user's initial query isn't the most effective way to search the knowledge base. Query transformation techniques aim to bridge this gap.
-
Query Expansion/Rewriting: An LLM can be used to rephrase or expand the user's query into several alternative queries that might yield better retrieval results. This helps cover synonyms, different phrasings, or related concepts.
- Example: User query: "How do I expense travel?" LLM rewrites to: "Travel reimbursement policy," "Submitting expense reports for business trips," "Company guidelines for travel costs."
-
Query Decomposition: For complex, multi-part questions, an LLM can break them down into simpler, atomic sub-queries. Each sub-query can then be executed independently, and the results combined.
- Example: User query: "What are the benefits of the new healthcare plan, and how do I enroll?" Decomposed into: 1. "What are the benefits of the new healthcare plan?" 2. "How do I enroll in the new healthcare plan?"
-
Hypothetical Document Embeddings (HyDE): This innovative technique involves using an LLM to generate a hypothetical answer to the user's query before retrieval. This hypothetical answer, being semantically rich and comprehensive, is then embedded. This embedding is often more effective for retrieval than the short, potentially ambiguous original query, as it captures the essence of what a good answer would look like.
- Example: User query: "What's the capital of France?" HyDE generates: "Paris is the capital and most populous city of France, located on the River Seine." This generated text's embedding is then used to find documents about Paris.
Context Augmentation and Prompt Engineering for RAG: Making Sense of What's Found
Once relevant context is retrieved, how it's presented to the LLM and how the LLM is instructed to use it are critical for generating high-quality answers.
-
Context Compression/Summarization: Passing raw, lengthy retrieved documents to the LLM can be inefficient (token limits, cost) and introduce noise. Techniques like LLM-powered reranking or summarization can distill the retrieved context. A smaller, faster LLM can be used to identify the most salient sentences or paragraphs from the retrieved chunks, or even summarize them, before passing the condensed version to the main generative LLM.
- Example: If 10 document chunks are retrieved, a smaller LLM might identify the 3 most relevant sentences across those chunks, or generate a 50-word summary of the key points, which is then passed to the main LLM.
-
Structured Prompting: Clearly delineating the retrieved context from the instructions within the prompt is vital. Using specific tags or sections (e.g.,
<context>,<query>,<instructions>) helps the LLM understand its role and where to find the information it needs.- Example:
You are an expert assistant. Answer the user's question based ONLY on the provided context. <context> [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] </context> <query> What is the policy on vacation days? </query>You are an expert assistant. Answer the user's question based ONLY on the provided context. <context> [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] </context> <query> What is the policy on vacation days? </query>
- Example:
-
Self-Correction/Self-Reflection: This involves enabling the LLM to critically evaluate its own generated answer against the retrieved context. If the LLM identifies inconsistencies or missing information, it can either refine its answer or even trigger another retrieval step. This adds a layer of robustness and reduces the likelihood of subtle hallucinations.
- Example: After generating an answer, the LLM might be prompted: "Review your answer. Does it directly address the query? Is every statement supported by the provided context? If not, identify the unsupported parts."
Evaluating RAG Systems: Ensuring Quality and Reliability
Building a RAG system is one thing; ensuring it performs reliably and accurately is another. Robust evaluation is paramount, especially in enterprise settings.
-
Retrieval Metrics: These measure how well the system finds relevant documents:
- Recall: Percentage of relevant documents retrieved out of all relevant documents.
- Precision: Percentage of retrieved documents that are actually relevant.
- MRR (Mean Reciprocal Rank): Measures the quality of ranked search results, giving higher scores if the first relevant item is ranked higher.
- NDCG (Normalized Discounted Cumulative Gain): A more sophisticated ranking metric that considers the relevance of items and their position in the result list.
-
Generation Metrics: These assess the quality of the LLM's answer:
- Faithfulness (or groundedness): Does the generated answer only contain information supported by the retrieved context? (Crucial for RAG!)
- Answer Relevance: Is the generated answer directly relevant to the user's query?
- Context Relevance: Are the retrieved documents actually relevant to the query, even if the LLM didn't use all of them? (Important for debugging retrieval).
-
End-to-End Metrics & Frameworks: Tools like Ragas, TruLens, and ARES (Automated RAG Evaluation System) provide comprehensive frameworks to evaluate RAG systems holistically, often using smaller LLMs to act as evaluators. They can automatically score faithfulness, relevance, and other metrics, significantly streamlining the evaluation process.
-
Human-in-the-Loop Evaluation: Despite sophisticated automated metrics, human review remains indispensable. Subject matter experts can provide invaluable feedback on the accuracy, completeness, and usability of answers, especially for complex or sensitive domains.
Enterprise-Grade Considerations: From PoC to Production
Deploying RAG in an enterprise environment introduces a unique set of challenges and requirements beyond mere technical implementation.
-
Data Security and Privacy: This is non-negotiable. RAG systems must adhere to strict data governance policies (e.g., GDPR, HIPAA, CCPA). This means:
- Access Control: Ensuring only authorized users can access specific data.
- Data Masking/Redaction: Automatically identifying and obscuring sensitive information before it's embedded or presented to the LLM.
- Secure Vector Stores: Choosing vector databases with robust security features, encryption at rest and in transit, and private network deployments.
- Auditing: Logging all data access and LLM interactions.
-
Scalability and Performance: Enterprise knowledge bases can contain millions or billions of documents. The RAG system must be able to:
- Handle massive document ingestion and indexing efficiently.
- Process high volumes of concurrent user queries with low latency.
- Scale underlying infrastructure (vector stores, embedding models, LLM inference) dynamically.
-
Latency: Users expect near-instantaneous responses. Optimizing every step—query embedding, vector search, context compression, and LLM inference—is critical. Caching mechanisms, efficient model choices, and optimized infrastructure play a key role.
-
Version Control and Knowledge Base Management: Enterprise data is dynamic. Policies change, new documents are added, old ones are retired. A robust RAG system needs:
- Automated Indexing Pipelines: To keep the vector store up-to-date.
- Versioned Data: The ability to query historical versions of documents or revert to previous states of the knowledge base.
- Conflict Resolution: Handling overlapping or contradictory information.
-
Observability and Monitoring: Production RAG systems require comprehensive monitoring of:
- System Health: Latency, error rates, resource utilization.
- RAG-Specific Metrics: Retrieval accuracy, generation quality, hallucination rates (if detectable).
- User Feedback: Mechanisms for users to rate answers and report issues. This feedback loop is crucial for continuous improvement.
-
Multi-modal RAG: Many enterprise knowledge bases aren't just text. They include images, tables, diagrams, audio, and video. Multi-modal RAG extends the concept by:
- Multi-modal Embeddings: Creating embeddings that capture the meaning across different modalities (e.g., an image of a product linked to its text description).
- Retrieving Mixed Content: A query might retrieve a relevant document and a relevant image.
- LLMs Capable of Multi-modal Understanding: Using models like GPT-4V or Gemini that can process and generate responses based on both text and visual inputs.
- Example: In manufacturing, a technician might ask about a specific machine part. Multi-modal RAG could retrieve the part's technical manual (text) and its schematic diagram (image), allowing the LLM to explain the part's function and visually highlight it.
The Impact: RAG as an Enterprise Game-Changer
RAG is fundamentally changing how enterprises interact with their vast troves of data.
- Customer Service: Empowering chatbots and agents with instant access to accurate, up-to-date product information, troubleshooting guides, and customer histories.
- Legal & Compliance: Rapidly searching complex legal documents, identifying relevant precedents, and ensuring regulatory adherence.
- Healthcare: Assisting medical professionals with access to the latest research, patient records, and drug information, while maintaining strict privacy.
- Internal Knowledge Management: Creating intelligent assistants that can answer employee questions about HR policies, IT support, or project documentation, reducing reliance on human experts.
- Financial Services: Analyzing market reports, regulatory filings, and internal financial data for insights and compliance.
- Software Development: Providing context-aware code generation, documentation assistance, and bug resolution by grounding LLMs in internal codebases and best practices.
Conclusion: The Future is Grounded
Retrieval-Augmented Generation has moved from an academic concept to an indispensable tool for building reliable, accurate, and scalable LLM applications. Its ability to mitigate core LLM limitations—hallucinations, outdated knowledge, and lack of specificity—makes it particularly vital for enterprise environments where accuracy and trustworthiness are paramount.
The rapid advancements in retrieval techniques, query optimization, context augmentation, and robust evaluation frameworks are continually pushing the boundaries of what RAG can achieve. As enterprises increasingly integrate LLMs into their core operations, RAG will not just be a feature; it will be the foundational architecture that unlocks the true potential of AI, ensuring that our intelligent systems are not just fluent, but also factually grounded and trustworthy. For any AI practitioner or enthusiast looking to build impactful, real-world LLM applications, mastering RAG and its evolving landscape is no longer optional—it's essential.