Edge AI: Unleashing the Power of IoT Data Deluge
The explosion of IoT devices creates a massive data challenge. Traditional cloud AI struggles with this volume. Discover how Edge AI processes data closer to its source, transforming raw IoT data into actionable insights for smarter, more efficient systems.
The world is awash in data, and nowhere is this more evident than at the "edge" – the sprawling network of IoT devices that increasingly permeate our lives, industries, and infrastructure. From smart sensors monitoring environmental conditions to cameras overseeing public spaces, and from industrial machinery optimizing production lines to wearables tracking our health, billions of interconnected devices are generating an unprecedented volume of information. This deluge of data presents both an enormous opportunity and a significant challenge for artificial intelligence.
Traditionally, AI models are trained in centralized cloud environments, where data from various sources is aggregated, processed, and used to refine algorithms. While effective for many applications, this centralized paradigm buckles under the weight of IoT data. Imagine sending every frame from thousands of surveillance cameras, every millisecond of telemetry from factory robots, or every heartbeat from millions of smartwatches to a distant cloud server. The sheer bandwidth requirements, the inherent latency, the costs, and critically, the privacy implications make this approach unsustainable and often, impossible. This is where the convergence of Edge AI and a revolutionary paradigm called Federated Learning (FL) steps in, offering a path to unlock the true potential of IoT while respecting its inherent constraints.
The Imperative for Edge AI and Its Centralized Challenges
Edge AI refers to the deployment of AI models directly on edge devices or local edge servers, allowing data processing and inference to happen closer to the data source. This approach offers several compelling advantages:
- Low Latency: Real-time decision-making is crucial for applications like autonomous vehicles, industrial control, and critical infrastructure monitoring. Processing data locally eliminates the round-trip delay to the cloud.
- Reduced Bandwidth Usage: Instead of constantly streaming raw data, only aggregated insights or necessary updates are sent, significantly cutting down network traffic and associated costs.
- Improved Reliability: Edge systems can operate effectively even with intermittent or no cloud connectivity, ensuring continuous operation in remote or unstable network environments.
- Enhanced Privacy: Sensitive data remains on the device, minimizing exposure and reducing the risk of breaches during transit or storage in a central repository.
However, training sophisticated AI models directly on these diverse and often resource-constrained edge devices presents its own set of formidable challenges:
- Data Privacy Concerns: IoT devices often collect highly sensitive information – personal health metrics, surveillance footage, proprietary industrial telemetry. Transmitting this raw data to a central server for training is a non-starter due to regulatory compliance (e.g., GDPR, CCPA), ethical considerations, and competitive concerns.
- Bandwidth and Latency Bottlenecks: Even if privacy wasn't an issue, the sheer volume of data generated by billions of devices would overwhelm network infrastructure if all of it were uploaded for centralized training.
- Heterogeneity of Edge Devices: IoT devices vary wildly in their computational power, memory, storage, and battery life. A "one-size-fits-all" training approach is impractical.
- Data Silos: Data is naturally fragmented across individual devices or within specific organizations. Aggregating it for a global model is difficult, if not impossible, due to ownership and privacy barriers.
These challenges highlight a fundamental tension: we need to leverage the vast, distributed data at the edge to train powerful AI models, but we cannot centralize this data. Federated Learning emerges as the elegant solution to this dilemma.
Federated Learning: The Core Principle of Collaborative Intelligence
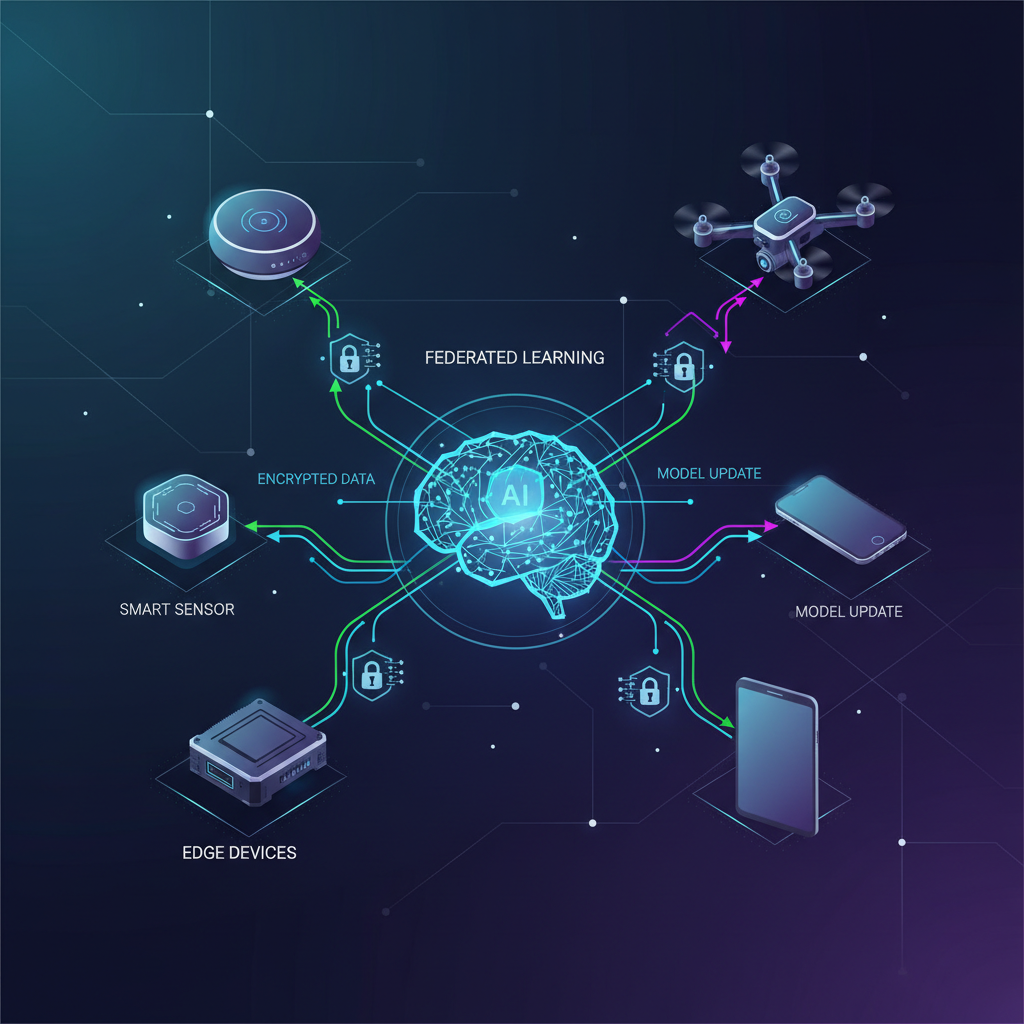
Federated Learning is a distributed machine learning paradigm that enables multiple entities (e.g., edge devices) to collaboratively train a shared prediction model while keeping their training data localized. The core principle is simple yet profound: bring the model to the data, not the data to the model.
Let's break down the iterative process:
- Global Model Distribution: A central server (or an aggregating edge node) initializes a global AI model (e.g., a neural network) and distributes it to a selected subset of participating edge devices.
- Local Training: Each chosen edge device downloads the current global model. It then trains this model locally using its own private, raw dataset. Critically, this data never leaves the device.
- Model Update Sharing: Instead of sending its raw data back, each device computes and sends only its model updates (e.g., gradients, weight differences, or learned parameters) to the central server. These updates are typically much smaller than the raw data itself.
- Global Model Aggregation: The central server receives model updates from multiple devices. It then aggregates these updates, typically by averaging them (a process known as Federated Averaging or FedAvg), to create an improved version of the global model.
- Global Model Redistribution: The newly improved global model is then sent back to the devices, initiating the next round of local training.
This cycle repeats until the model converges to a desired performance level or a predefined number of training rounds are completed. The beauty of FL lies in its ability to harness the collective intelligence of distributed data sources without ever compromising the privacy of individual data points.
Types of Federated Learning
While the core principle remains, FL manifests in different forms depending on the data distribution:
- Horizontal Federated Learning (HFL): Also known as "sample-based FL," this is the most common type. It applies when different devices share the same feature space (i.e., they collect similar types of data attributes) but have different data samples. For example, multiple smart homes training a common energy prediction model, where each home has different residents and energy consumption patterns, but all collect data like temperature, time of day, and appliance usage.
- Vertical Federated Learning (VFL): Also known as "feature-based FL," this is relevant when devices or organizations share the same sample ID space (i.e., they have data about common entities) but possess different feature sets. For instance, two banks collaborating on fraud detection for common customers. Bank A might have transaction history, while Bank B has credit scores. VFL allows them to train a joint model without exchanging their proprietary customer data. While less common in pure IoT, it's highly relevant for inter-organizational collaborations at the edge.
- Federated Transfer Learning: This approach leverages the power of pre-trained models. A base model, often trained on a large public dataset, is adapted and fine-tuned in a federated manner. This can significantly reduce the training time and data requirements for edge devices, especially when local data is scarce.
Recent Developments and Emerging Trends: Pushing the Boundaries of FL
The field of Federated Learning is rapidly evolving, driven by the increasing demand for privacy-preserving and efficient AI. Recent developments are addressing key challenges and expanding its capabilities:
- Handling Heterogeneous Edge Devices: IoT environments are inherently diverse. Research is focusing on adaptive aggregation strategies, client selection mechanisms (e.g., selecting devices with sufficient resources or data), and personalized FL approaches to account for devices with vastly different computational power, memory, and network connectivity.
- Communication Efficiency: The bottleneck in FL often shifts from data transfer to model update transfer. Techniques like sparsification (sending only the most significant weights), quantization (reducing the precision of weights), and compression of model updates are crucial for reducing communication overhead, especially for constrained IoT networks.
- Enhanced Security and Privacy: While FL offers inherent privacy advantages, it's not foolproof. Malicious actors could potentially infer sensitive information from aggregated updates or inject poisoned updates. Advanced techniques are being integrated:
- Differential Privacy (DP): Adding carefully calibrated noise to model updates before sending them to the server, providing a mathematical guarantee against individual data inference.
- Homomorphic Encryption (HE): A cryptographic method that allows computations to be performed on encrypted data without decrypting it. This ensures that even the central server cannot see the raw model updates, let alone the data.
- Secure Multi-Party Computation (SMC): Distributing computation across multiple parties in such a way that no single party learns the others' inputs, even during the aggregation process.
- Blockchain for FL: Using blockchain to provide transparency, immutability, and auditability for FL processes, potentially incentivizing participation and ensuring the integrity of model updates.
- Personalized Federated Learning (PFL): A single global model might not be optimal for all diverse edge devices, especially when data distributions are highly non-IID. PFL explores methods to derive personalized models for each client while still benefiting from global knowledge. This can involve fine-tuning the global model locally, meta-learning approaches, or learning a global model that serves as a strong initialization for local personalization.
- Non-IID Data Handling: Data from IoT devices is rarely Independent and Identically Distributed (non-IID). For example, a smart home's energy consumption patterns will differ significantly from another. This non-IID nature can degrade FL performance. Algorithms like FedProx and SCAFFOLD are designed to mitigate this by adjusting local optimization or compensating for client drift.
- Resource-Aware FL: Optimizing FL training schedules based on dynamic factors like device battery levels, network availability, and current computational load. This ensures that training doesn't unduly burden devices or fail due to resource constraints.
- Integration with Edge Orchestration: As edge computing ecosystems mature, effective deployment and management of FL training need to integrate seamlessly with existing edge orchestration frameworks (e.g., Kubernetes for edge, OpenYurt). This allows for dynamic client selection, resource allocation, and lifecycle management of FL tasks.
Practical Applications and Transformative Use Cases
The theoretical elegance of Federated Learning translates into powerful, real-world applications across numerous sectors, fundamentally changing how AI is deployed at the edge:
1. Smart Cities
- Traffic Management: Individual vehicles (edge devices) can collaboratively train models for real-time traffic prediction, route optimization, and accident detection. Each vehicle contributes its local driving data and observations without revealing individual travel patterns, leading to a more efficient and safer urban mobility system.
- Smart Surveillance: Edge cameras deployed in public spaces can detect anomalies (e.g., abandoned packages, unusual crowds, trespassers) and collaboratively improve their detection models. Raw video feeds remain local, ensuring public privacy while enhancing security capabilities.
- Environmental Monitoring: Distributed sensors across a city can train models for hyper-local air quality prediction, noise pollution mapping, or even identifying pollution sources, all without centralizing sensitive location-specific data.
2. Healthcare & Wearables
- Personalized Health Monitoring: Smartwatches, continuous glucose monitors, and other medical IoT devices can train highly personalized models to predict health risks (e.g., heart attack, diabetes onset, seizure prediction) based on an individual's unique physiological data. This happens directly on the device or a local gateway, ensuring patient privacy while providing proactive health insights.
- Drug Discovery & Disease Research: Multiple hospitals or research institutions can collaborate on training models for disease diagnosis, prognosis, or drug efficacy. FL allows them to pool their collective knowledge without ever sharing sensitive patient records, accelerating medical breakthroughs.
3. Industrial IoT (IIoT) & Manufacturing
- Predictive Maintenance: Machines on a factory floor can train models to predict equipment failures, optimizing maintenance schedules and reducing costly downtime. Proprietary operational data, which is often a trade secret, never leaves the factory network, allowing companies to leverage AI without compromising competitive advantage.
- Quality Control: Edge cameras on assembly lines can collaboratively train defect detection models. As new types of defects emerge, the models can be updated across multiple production lines, improving accuracy and consistency without centralizing sensitive production imagery.
4. Smart Homes & Consumer Electronics
- Voice Assistants: Smart speakers and virtual assistants can learn individual user preferences, accents, and commands more effectively. The models adapt to household-specific language patterns without sending private conversations to the cloud, enhancing both utility and privacy.
- Smart Appliances: Refrigerators can learn consumption patterns to optimize energy use, and thermostats can learn comfort preferences. All this learning happens locally, ensuring that personal habits remain private within the home.
5. Autonomous Vehicles
- Collaborative Perception: Fleets of autonomous vehicles can share model updates to improve object detection, lane keeping, and pedestrian recognition capabilities. This enhances safety and robustness across the entire fleet, as each vehicle learns from the collective experience without sharing raw sensor data (which could reveal routes or sensitive environmental details).
- Route Optimization: Vehicles can collaboratively learn optimal routes, traffic patterns, and road conditions, leading to more efficient navigation and reduced congestion.
Challenges for Practitioners: Navigating the FL Landscape
While the promise of Federated Learning is immense, its implementation comes with its own set of practical challenges that practitioners must address:
- Non-IID Data: The performance degradation of FL models when data distributions vary widely across devices remains a significant research and engineering challenge. Developing robust aggregation algorithms and personalization strategies is key.
- System Heterogeneity: Managing and optimizing training across a vast array of devices with diverse computational capabilities, memory, storage, battery life, and network conditions requires sophisticated client selection, resource management, and adaptive training protocols.
- Communication Overhead: Even with optimized updates, transmitting model parameters can still be a bottleneck for very large models (e.g., large language models) or in environments with extremely slow or intermittent network connectivity.
- Security & Trust: Ensuring that malicious clients cannot poison the global model (e.g., by sending adversarial updates) or infer private data from aggregated updates (e.g., through reconstruction attacks) requires robust cryptographic techniques and anomaly detection.
- Model Personalization vs. Generalization: Striking the right balance between creating a general global model that benefits from collective knowledge and allowing for personalized models that cater to individual device needs is a complex optimization problem.
- Deployment & Management: Orchestrating FL training across a vast, dynamic, and potentially unreliable number of edge devices in a robust, scalable, and fault-tolerant manner is a significant operational challenge. This includes client selection, update scheduling, and failure recovery.
- Regulatory Compliance: Navigating the complex and evolving landscape of data privacy regulations (e.g., GDPR, CCPA, HIPAA) when designing and deploying FL systems requires careful legal and technical consideration.
Resources for AI Practitioners and Enthusiasts
For those eager to dive deeper into this transformative field, a wealth of resources is available:
- Foundational Papers:
- "Communication-Efficient Learning of Deep Networks from Decentralized Data" (McMahan et al., 2017): This seminal paper introduced Federated Averaging (FedAvg) and laid the groundwork for modern FL.
- Keep an eye on recent publications from top-tier AI conferences like NeurIPS, ICML, ICLR, AAAI, and KDD, as well as dedicated workshops on Federated Learning (e.g., FL-IJCAI, FL-ICML).
- Open-Source Frameworks/Libraries:
- TensorFlow Federated (TFF): An open-source framework developed by Google specifically for implementing federated learning. It offers a high-level API for expressing FL computations and a low-level API for research.
- PySyft (OpenMined): A Python library for secure, privacy-preserving deep learning. It integrates with PyTorch and TensorFlow and includes tools for FL, differential privacy, and homomorphic encryption.
- FATE (Federated AI Technology Enabler): An industrial-grade FL framework developed by Webank, supporting various FL algorithms and security features.
- Online Courses & Tutorials: Many universities and online learning platforms are now offering specialized courses or modules on Federated Learning, covering both theoretical foundations and practical implementation.
- Conferences & Workshops: Attending or following the proceedings of dedicated workshops on Federated Learning at major AI conferences is an excellent way to stay abreast of the latest research and developments.
Conclusion
Federated Learning for Edge AI in IoT is not merely a theoretical concept; it's rapidly becoming a practical necessity for unlocking the full potential of connected devices while respecting privacy and overcoming infrastructure limitations. The explosive growth of IoT data, coupled with the imperative for local processing, has created a fertile ground for FL to flourish. By enabling collaborative model training without centralizing sensitive data, FL offers a powerful paradigm shift, addressing critical concerns around privacy, bandwidth, and latency.
For AI practitioners and enthusiasts, understanding and contributing to this field offers immense opportunities. It's a domain where cutting-edge research in distributed systems, cryptography, machine learning, and network optimization converges to build truly intelligent, scalable, and privacy-preserving systems. As we move towards an increasingly interconnected and data-rich future, Federated Learning will undoubtedly play a pivotal role in shaping the next generation of AI applications across countless industries, making our smart environments more intelligent, secure, and respectful of individual privacy.