Federated Learning: Unlocking the Full Potential of Edge AI for Privacy and Efficiency
Explore how Federated Learning (FL) revolutionizes Edge AI by enabling collaborative model training directly on devices, addressing privacy concerns, resource constraints, and the challenges of managing vast IoT data at the edge. Discover its critical role in building a future of ubiquitous, personalized, and privacy-preserving intelligent systems.
The digital world is awash with data, and an ever-increasing portion of it originates at the "edge" – from billions of IoT devices, sensors, and mobile phones. This proliferation of data at the source presents both immense opportunities and significant challenges. While Edge AI brings intelligence closer to where data is generated, reducing latency and bandwidth, it grapples with inherent limitations: privacy concerns, resource constraints (compute, memory, battery), and the sheer scale of managing diverse devices.
Enter Federated Learning (FL), a paradigm shift in machine learning that promises to unlock the full potential of Edge AI by enabling collaborative model training without centralizing raw data. This approach is not just a technical curiosity; it's a critical enabler for a future where intelligent systems are ubiquitous, personalized, and privacy-preserving, even on the most resource-constrained devices.
The Confluence of Trends: Why Federated Learning is Crucial for Edge AI
Federated Learning sits at the powerful intersection of several high-impact technological and societal trends, making it an indispensable tool for the next generation of AI:
-
Edge AI's Promise and Predicament: The move towards Edge AI is driven by the need for real-time inference, reduced cloud dependence, and enhanced reliability. Imagine autonomous vehicles making split-second decisions or smart factories predicting equipment failures instantly. However, training these models traditionally requires vast amounts of data to be sent to a central cloud, which is often impractical due to bandwidth limitations, latency, and data privacy regulations.
-
The Privacy Imperative: In an era of GDPR, CCPA, and growing public awareness, data privacy is no longer optional. IoT devices, from health wearables to smart home sensors, collect highly sensitive personal data. Centralizing this data for training poses significant privacy risks and regulatory hurdles. Federated Learning offers a compelling solution by keeping raw data on the device, sharing only model updates.
-
Resource Constraints as a Design Principle: IoT devices are, by definition, resource-constrained. They operate on limited power, possess modest computational capabilities, and often rely on intermittent or low-bandwidth network connections. Traditional distributed training methods, designed for data centers, are ill-suited for this environment. FL must adapt to these limitations, not just overcome them.
-
Scalability and Heterogeneity: The IoT landscape is incredibly diverse, encompassing everything from tiny microcontrollers to powerful edge gateways. Managing and training AI models across millions or billions of such heterogeneous devices, each with unique data distributions and capabilities, is a monumental challenge that FL aims to address.
How Federated Learning Works: A Privacy-Preserving Dance
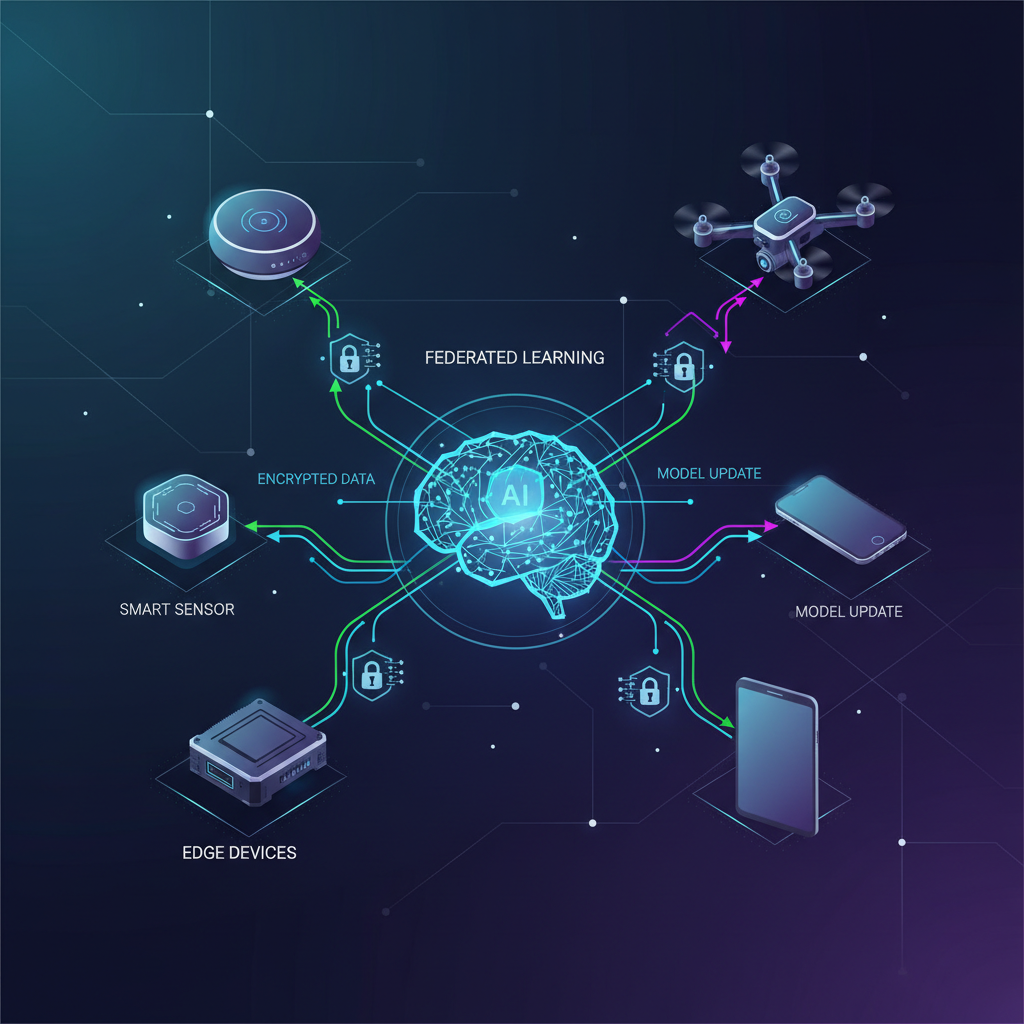
At its core, Federated Learning is a distributed machine learning approach that allows multiple clients (e.g., IoT devices, mobile phones) to collaboratively train a shared global model without exchanging their local training data. The process typically unfolds in rounds:
- Global Model Distribution: A central server (or orchestrator) sends the current version of the global model to a selected subset of participating edge devices.
- Local Training: Each selected device trains the model locally using its own private dataset. This training generates model updates (e.g., gradients or weight differences). Crucially, the raw data never leaves the device.
- Secure Update Aggregation: The devices send only these model updates (not the data) back to the central server. The server then aggregates these updates from multiple devices to create an improved version of the global model. This aggregation often involves averaging the updates (as in the popular FedAvg algorithm).
- Iteration: The new global model is then distributed for the next round of training, and the process repeats until the model converges or a desired performance is achieved.
This iterative process allows the global model to learn from the collective experience of all participating devices while respecting the privacy of individual data.
Tackling the Edge: Challenges of FL in Resource-Constrained Environments
While FL is a powerful concept, deploying it effectively on resource-constrained edge devices introduces several unique and complex challenges:
1. Communication Overhead: The Bandwidth Bottleneck
Even though FL transmits only model updates instead of raw data, these updates can still be substantial, especially for deep learning models with millions of parameters. Frequent communication rounds can strain limited network bandwidth, consume battery life, and introduce significant latency, particularly in environments with unreliable or slow connections (e.g., cellular networks, LPWANs).
2. Computational Cost: The On-Device Training Burden
Training even a small neural network on a low-power microcontroller or an embedded system can be computationally intensive. Edge devices often lack the powerful GPUs or ample memory found in data centers. This limits the complexity of models that can be trained locally and impacts the speed and energy efficiency of the training process.
3. Data Heterogeneity (Non-IID Data): The "Personalization vs. Generalization" Dilemma
A fundamental assumption in traditional distributed ML is that data is identically and independently distributed (IID) across clients. In FL for edge devices, this is rarely true. A smart home's data will differ significantly from a factory sensor's data, and even within the same application, individual user data will vary. This "Non-IID" data distribution can lead to:
- Model Divergence: Local models might drift in different directions, making global aggregation less effective.
- Reduced Global Performance: A single global model might perform poorly on individual devices whose data distribution deviates significantly from the global average.
- Fairness Issues: The model might perform exceptionally well for devices with abundant data, but poorly for those with sparse or unique data.
4. Device Heterogeneity: The Diverse Ecosystem
The edge ecosystem is incredibly diverse. Devices vary wildly in:
- Computational Power: From tiny microcontrollers to powerful edge gateways.
- Memory: Kilobytes to gigabytes.
- Battery Life: Always-on to battery-powered, requiring energy-efficient operations.
- Network Connectivity: High-speed Wi-Fi to intermittent cellular or satellite links.
- Availability: Some devices might be always online, while others connect sporadically.
Designing an FL system that can robustly handle this extreme heterogeneity is a significant hurdle.
5. Security and Trust: Beyond Privacy
While FL inherently offers privacy benefits, it's not immune to security threats. Malicious clients could:
- Poison the Model: Inject carefully crafted, erroneous updates to degrade the global model's performance or introduce backdoors.
- Infer Private Data: Sophisticated inference attacks might attempt to reconstruct parts of the local training data from the shared model updates.
- Sybil Attacks: A single adversary might control multiple devices to amplify their malicious influence.
Innovative Solutions: Techniques for Robust FL at the Edge
Researchers and engineers are actively developing a plethora of techniques to overcome these challenges, making FL a practical reality for resource-constrained edge AI.
1. Communication Efficiency: Less is More
To combat bandwidth limitations, the focus is on drastically reducing the size of model updates:
- Sparsification (Gradient Pruning): Instead of sending all model parameters or gradients, only the most significant ones (e.g., those exceeding a certain threshold) are transmitted. This can reduce communication by orders of magnitude.
- Example: Imagine a neural network with 10 million parameters. Instead of sending all 10 million gradient updates, a sparsification technique might send only the top 1% (100,000) largest updates.
- Quantization: Reducing the precision of the transmitted model updates. Instead of using 32-bit floating-point numbers, updates might be represented using 8-bit integers or even 1-bit (binary) values. This significantly shrinks the data size.
- Example: A gradient value of
0.00345678might be quantized to0.003or even mapped to a discrete integer value within a predefined range, then de-quantized at the server.
- Example: A gradient value of
- Federated Averaging (FedAvg) Variants: The original FedAvg algorithm is a good baseline, but many variants optimize communication. For instance, some approaches allow clients to perform more local training epochs before sending updates, reducing communication frequency at the cost of potentially slower convergence or increased local computation.
- Secure Aggregation Protocols: These protocols, often based on cryptographic techniques like Secure Multi-Party Computation (SMC), allow the server to compute the sum of updates without seeing individual client updates. While offering strong privacy, they can introduce communication and computational overhead.
2. On-Device Training Optimization: Smart Models for Smart Devices
Making local training feasible on constrained hardware requires intelligent model design and optimization:
- Model Compression Techniques:
- Pruning: Removing redundant connections or neurons from a neural network without significantly impacting performance.
- Quantization (Model Quantization): Reducing the numerical precision of model weights and activations (e.g., from 32-bit floats to 8-bit integers) during inference and sometimes during training.
- Knowledge Distillation: Training a smaller "student" model to mimic the behavior of a larger, more complex "teacher" model. The student model is then deployed on the edge.
- Efficient Architectures: Designing neural networks specifically for edge devices, characterized by fewer parameters, shallower layers, and optimized operations. Examples include MobileNet, EfficientNet, and ShuffleNet.
- Hardware-aware FL: Leveraging specialized edge AI accelerators (e.g., NPUs, TPUs, DSPs) that are increasingly common in modern edge devices. FL frameworks can be designed to offload computations to these accelerators when available.
3. Addressing Non-IID Data: Personalization and Adaptation
Handling diverse local data distributions is one of the most active research areas in FL:
- Personalized Federated Learning (pFL): Instead of aiming for a single global model, pFL seeks to create personalized models for each device while still benefiting from collaborative learning. Techniques include:
- Meta-Learning: Training a model that can quickly adapt to new, unseen tasks or data distributions with minimal local training.
- Multi-Task Learning: Treating each device's learning task as a distinct but related task, sharing common layers or knowledge across them.
- Fine-tuning: Training a robust global model, then allowing each device to fine-tune a small portion of the model (e.g., the last few layers) using its local data.
- Client Selection Strategies: Intelligently selecting which devices participate in each training round. This can involve:
- Selecting devices with high-quality data.
- Prioritizing devices with diverse data to improve global model generalization.
- Considering device availability, battery levels, and network conditions to ensure reliable participation.
- Data Augmentation and Synthetic Data Generation: While raw data stays on the device, techniques that locally augment data or generate synthetic data (without revealing original patterns) can help devices contribute more effectively, especially if their local datasets are small.
4. Enhanced Privacy Guarantees: Beyond Data Isolation
While FL prevents raw data sharing, advanced privacy techniques can further strengthen its guarantees:
- Differential Privacy (DP): Adding carefully calibrated noise to the model updates before they are sent to the server. This makes it statistically difficult to infer information about any single individual's data from the aggregated updates.
- Example: Before a device sends its gradient vector, a small amount of random noise is added to each element of the vector. The amount of noise is controlled by a privacy budget parameter (epsilon).
- Secure Multi-Party Computation (SMC) / Homomorphic Encryption (HE): These cryptographic techniques allow computations (like aggregation) to be performed on encrypted data. The server can aggregate encrypted updates without ever decrypting them, and thus never sees the individual client contributions.
- Example: Clients encrypt their model updates before sending them. The server performs an aggregation operation (e.g., summation) directly on the encrypted values, producing an encrypted sum. Only a trusted party (or the clients themselves) can decrypt the final aggregated model. While powerful, these techniques often introduce significant computational and communication overhead.
Real-World Impact: Federated Learning in Action
Federated Learning is not just a theoretical concept; it's already powering critical applications and poised to revolutionize many more:
- Mobile Keyboard Prediction (Google Gboard): One of the most widely cited examples. Gboard uses FL to improve next-word prediction and emoji suggestions. Your phone learns your typing patterns locally, and these learnings (model updates) contribute to a global model, making the keyboard smarter for everyone without sending your personal messages to Google's servers.
- Personalized Health Monitoring: Wearable devices (smartwatches, fitness trackers) can collaboratively train models to detect anomalies, predict health risks, or personalize exercise recommendations. Sensitive health data remains on the device, while the collective intelligence improves the accuracy of health insights.
- Smart Home Automation: Devices like smart thermostats, security cameras, and voice assistants can learn user preferences, routines, and environmental patterns. FL allows these devices to adapt to individual household needs while maintaining the privacy of daily activities. For instance, a smart lighting system could learn optimal lighting schedules for a home without uploading all occupancy data to the cloud.
- Industrial IoT (Predictive Maintenance): In factories and industrial settings, sensors on machinery generate vast amounts of operational data. FL enables different machines or even different factories to collaboratively train models to predict equipment failures, optimize maintenance schedules, or improve efficiency, all without sharing proprietary operational data across organizational boundaries.
- Autonomous Driving: Vehicles can learn from each other's driving experiences. For example, cars could collaboratively improve object detection models by sharing model updates derived from encountering new road conditions or obstacles, accelerating model development without sharing raw sensor footage (which is often massive and privacy-sensitive).
- Financial Fraud Detection: Banks could collaborate to build more robust fraud detection models by sharing model updates, rather than sensitive customer transaction data, improving the collective ability to identify new fraud patterns.
Practical Frameworks and Tools
The growing interest in FL has led to the development of several open-source frameworks that simplify its implementation:
- TensorFlow Federated (TFF): An open-source framework from Google designed for implementing FL. It provides a high-level API for expressing FL computations and a low-level API for researchers to experiment with new FL algorithms.
- PyTorch FATE (Federated AI Technology Enabler): An open-source project initiated by Webank, providing a secure computing framework for FL, supporting various FL algorithms and privacy-preserving techniques.
- Flower: A flexible and extensible FL framework that aims to be framework-agnostic (supporting TensorFlow, PyTorch, JAX, etc.). It's designed for ease of use and research prototyping.
- Edge AI Hardware Platforms: The increasing availability of specialized hardware like NVIDIA Jetson, Google Coral (Edge TPU), and Qualcomm AI Engine on Snapdragon platforms makes on-device training and inference more feasible, providing the computational backbone for FL at the edge.
Conclusion: The Future is Federated and Private
Federated Learning for resource-constrained Edge AI is more than just a niche research area; it's a foundational technology for building the next generation of intelligent, privacy-preserving, and efficient systems. By enabling collaborative learning without compromising data privacy, it unlocks the potential of billions of edge devices, transforming raw data into actionable intelligence directly at the source.
The journey is not without its hurdles – balancing communication efficiency with model performance, navigating data heterogeneity, and ensuring robust security are ongoing challenges. However, the rapid pace of innovation in efficient FL algorithms, personalized learning techniques, and privacy-enhancing technologies is steadily paving the way.
For AI practitioners and enthusiasts, understanding Federated Learning is becoming increasingly crucial. It offers a unique blend of theoretical depth in distributed optimization and privacy-preserving machine learning, coupled with immense practical implications for real-world IoT deployments. As our world becomes ever more connected and data-rich, Federated Learning stands as a beacon, guiding us towards a future where AI is powerful, pervasive, and profoundly respectful of our privacy.