Federated Learning at the Edge: Revolutionizing AI in the IoT Era
The IoT generates a deluge of data, posing challenges for traditional AI. Federated Learning at the Edge offers a paradigm shift, enabling distributed AI model training while addressing privacy, bandwidth, and computational resource concerns.
The Internet of Things (IoT) has ushered in an era of unprecedented connectivity, with billions of devices generating a continuous deluge of data. From smart homes and wearable health monitors to industrial sensors and autonomous vehicles, these devices promise a future where our environments are smarter, more responsive, and more efficient. However, harnessing the true potential of this data for artificial intelligence has presented significant challenges, particularly around privacy, network bandwidth, and computational resources.
Enter Federated Learning (FL) at the Edge – a paradigm shift that is redefining how AI models are trained and deployed in the IoT landscape. This innovative approach offers a compelling solution to many of the bottlenecks inherent in traditional cloud-centric AI, promising a future where intelligence is distributed, privacy is paramount, and efficiency is optimized.
The Confluence of IoT, Edge AI, and the Data Deluge
The sheer volume of data generated by IoT devices is staggering. Consider a single smart city deployment with thousands of traffic cameras, environmental sensors, and public transport trackers. Transmitting all this raw data to a centralized cloud server for AI training is not only impractical due to bandwidth limitations and latency concerns but also incredibly costly. Moreover, the sensitivity of much of this data – be it personal health records from wearables, video feeds from surveillance systems, or proprietary operational data from industrial machinery – raises profound privacy and regulatory concerns (e.g., GDPR, HIPAA).
Traditional AI models typically rely on a centralized approach: collect all data, send it to a powerful cloud server, train the model, and then deploy the trained model for inference. While effective for many applications, this model breaks down when faced with the realities of modern IoT:
- Bandwidth Bottlenecks: Uploading petabytes of raw data from countless edge devices to the cloud is a logistical nightmare and a significant cost driver.
- Latency Issues: For real-time applications like autonomous driving or industrial control, sending data to the cloud for processing and awaiting a response introduces unacceptable delays.
- Privacy Risks: Centralizing sensitive data creates a single point of failure and a massive target for cyberattacks, making compliance with data protection regulations incredibly difficult.
- Resource Constraints: Edge devices often have limited power, memory, and processing capabilities, making on-device training or complex inference challenging.
Edge AI emerged as a partial solution, bringing AI inference closer to the data source. This allows for real-time decision-making and reduced latency. However, training and updating these edge models still largely relied on centralized data collection or periodic manual updates, which circled back to the original problems.
Federated Learning steps in to bridge this gap, offering a robust framework for collaboratively building intelligent systems while respecting the inherent constraints and sensitivities of the IoT ecosystem.
Understanding Federated Learning: A Collaborative Privacy-Preserving Approach
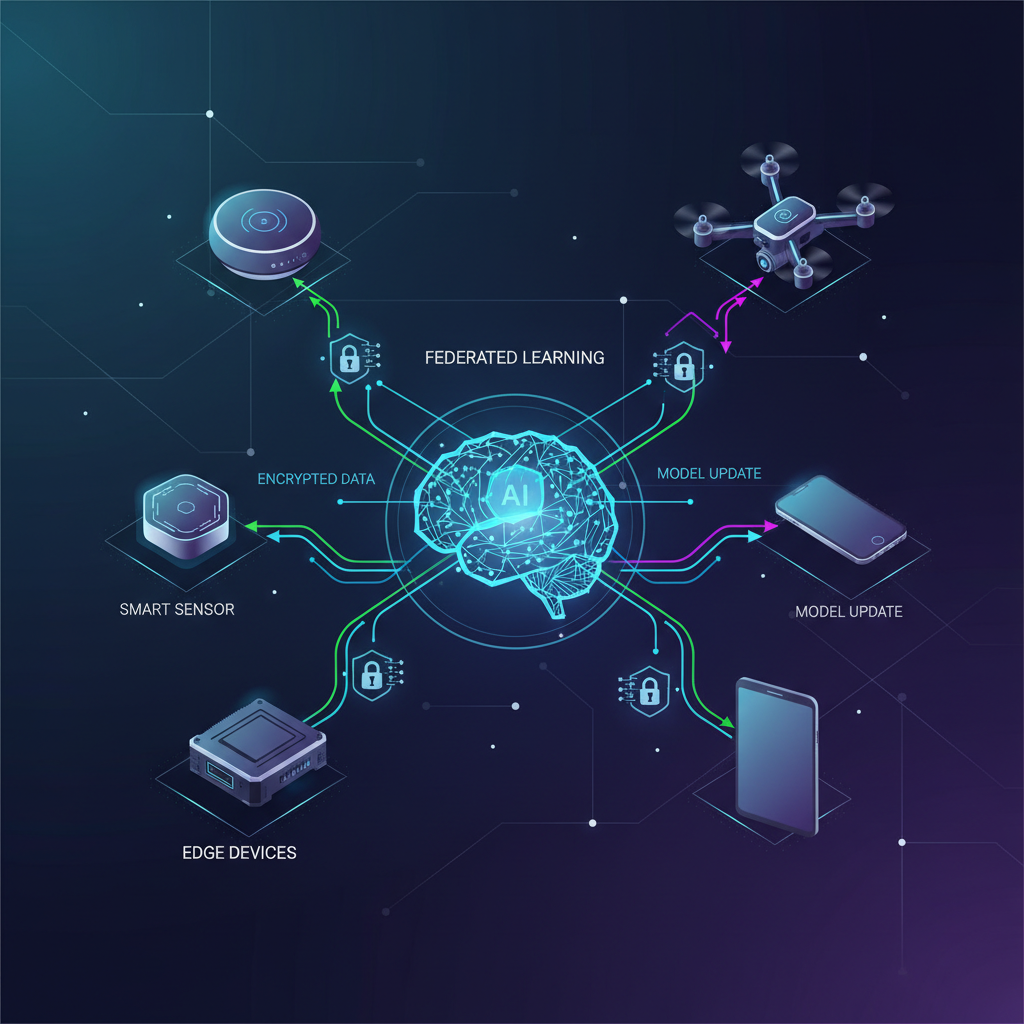
At its core, Federated Learning is a distributed machine learning paradigm that allows multiple clients (e.g., IoT devices) to collaboratively train a shared global model without ever exchanging their raw local data. Instead of sending data to the cloud, the process is inverted:
- Local Training: Each IoT device downloads the current version of the global model. It then trains this model locally on its own private dataset. This training process generates model updates, typically in the form of updated weights or gradients.
- Update Transmission: Only these model updates – which are significantly smaller and less privacy-sensitive than raw data – are sent back to a central server.
- Secure Aggregation: The central server receives updates from numerous participating devices. It then aggregates these updates, often using techniques like federated averaging (FedAvg), to create an improved version of the global model.
- Global Model Distribution: The newly aggregated global model is then sent back to the participating devices for the next round of local training, or to new devices for inference.
This iterative process continues, allowing the global model to learn from the collective experience of all participating devices without ever directly accessing their private data.
Key Benefits of Federated Learning in IoT and Edge AI
The synergy between Federated Learning and IoT at the edge unlocks a multitude of advantages that address the practical challenges of deploying AI in real-world distributed systems:
1. Unprecedented Privacy Preservation
This is arguably the most significant benefit. By keeping raw data on the device, FL drastically reduces the risk of data breaches and simplifies compliance with stringent privacy regulations like GDPR, HIPAA, and CCPA. For sensitive applications such as smart health, where personal medical data is involved, or smart homes, where voice commands and video feeds are processed, FL provides a critical layer of protection. Users retain control over their data, fostering trust and encouraging broader adoption of AI-powered IoT solutions.
2. Enhanced Bandwidth Efficiency
Instead of transmitting vast quantities of raw sensor readings, images, or audio files, FL only requires the transmission of compact model updates. These updates are typically orders of magnitude smaller than the raw data itself. This dramatically reduces network traffic, lowers data transfer costs, and makes AI deployments viable even in environments with limited or intermittent connectivity. For large-scale IoT deployments, this translates into substantial operational savings and improved system responsiveness.
3. Reduced Latency and Real-time Capabilities
While FL primarily addresses the training phase, its distributed nature contributes to lower inference latency. By improving the local models on edge devices, FL ensures that the most up-to-date and accurate models are available for immediate, on-device inference. This is crucial for applications requiring instantaneous decision-making, such as autonomous vehicles responding to road conditions or industrial systems detecting anomalies in real-time. The need to send data to the cloud and wait for a response is significantly minimized.
4. Scalability to Massive Device Fleets
FL is inherently designed for distributed environments, making it highly scalable. It can accommodate training contributions from millions of diverse IoT devices, allowing for continuous model improvement from a vast and ever-growing data stream. This contrasts sharply with centralized training, which often struggles with the logistical and computational overhead of ingesting data from such a large and disparate source.
5. Robustness to Connectivity Challenges
IoT devices often operate in environments with unreliable or intermittent network connectivity. With FL, devices can perform local training even when offline, storing model updates. Once a connection is re-established, they can upload their updates to the central server. This "train-then-upload" approach ensures that valuable local data is still utilized for model improvement, even if the device isn't continuously connected.
6. Potential for Personalization and Customization
While FL aims for a global model, it also opens doors for personalization. Techniques like "Federated Meta-Learning" or "Personalized FL" allow the global model to serve as a strong starting point, which individual devices can then fine-tune further on their unique local data. This enables models to adapt to specific user behaviors, environmental conditions, or device characteristics, leading to more relevant and effective AI applications without compromising the collective learning.
Emerging Trends and Overcoming Challenges
Despite its immense promise, Federated Learning, especially at the edge, is an active research area with several complex challenges that researchers and practitioners are actively addressing:
1. Heterogeneity of Edge Devices
IoT devices are incredibly diverse, varying widely in computational power, memory, battery life, and network capabilities. This heterogeneity means some devices can perform more intensive local training than others. FL algorithms need to be robust to these differences. Research focuses on adaptive aggregation strategies (e.g., weighting updates based on data size or device reliability) and asynchronous FL approaches (e.g., FedAsync) that don't require all devices to complete training simultaneously.
2. Data Skew (Non-IID Data)
A fundamental assumption in many machine learning algorithms is that data is identically and independently distributed (IID). However, data generated by individual IoT devices is often highly non-IID. For example, a smart home thermostat in one house will generate different data patterns than one in another, based on occupancy, user preferences, and climate. This "data skew" can significantly degrade the performance and convergence of FL models. Solutions include:
- Personalized FL: Allowing devices to adapt the global model to their local data.
- Advanced Aggregation: Developing more sophisticated aggregation rules that account for data distribution differences.
- Data Augmentation: Techniques to enrich local datasets.
3. Security and Trust Beyond Privacy
While FL enhances privacy, it's not immune to malicious attacks. A compromised or malicious client could send poisoned model updates designed to corrupt the global model (e.g., data poisoning, model poisoning attacks). Protecting against such threats requires:
- Secure Aggregation Protocols: Technologies like Homomorphic Encryption (HE) or Secure Multi-Party Computation (SMC) allow the server to aggregate updates without decrypting individual contributions, protecting against snooping.
- Robust Aggregation Techniques: Algorithms that can detect and filter out anomalous or malicious updates.
- Differential Privacy (DP): Adding carefully calibrated noise to model updates to provide provable privacy guarantees, making it harder to infer individual data points from the updates.
4. Resource Constraints on Edge Devices
Training even small models on resource-constrained edge devices can be challenging. This necessitates the adoption of "TinyML" principles and techniques such as:
- Model Quantization: Reducing the precision of model weights (e.g., from 32-bit floats to 8-bit integers) to decrease memory footprint and computational cost.
- Model Pruning: Removing redundant connections or neurons from a neural network without significant loss of accuracy.
- Knowledge Distillation: Training a smaller "student" model to mimic the behavior of a larger, more complex "teacher" model.
- Efficient Optimizers: Using optimizers specifically designed for low-resource environments.
5. Communication Overhead and Efficiency
Even with smaller updates, frequent communication between potentially millions of devices and a central server can still be a bottleneck. Research focuses on:
- Sparsification and Compression: Techniques to further reduce the size of model updates.
- Federated Dropout: Randomly selecting a subset of devices for each training round to reduce communication load.
- Asynchronous FL: Allowing devices to upload updates whenever they are ready, rather than waiting for a synchronized round.
- Hierarchical FL: Introducing intermediate aggregators (e.g., local gateways) to aggregate updates from clusters of devices before sending them to the central server.
6. Deployment, Orchestration, and Lifecycle Management
Managing and orchestrating FL training across thousands or millions of diverse, geographically dispersed, and often intermittently connected edge devices is a significant operational challenge. This includes:
- Device Selection: Deciding which devices participate in each training round.
- Model Versioning and Updates: Ensuring all devices have the correct model version.
- Monitoring and Debugging: Tracking training progress and identifying issues in a distributed environment.
- Frameworks: Platforms like Google's TensorFlow Federated (TFF), PySyft, and Flower are emerging to simplify the development and deployment of FL systems.
Practical Applications Across Industries
The practical implications of Federated Learning at the edge are vast and transformative, impacting numerous sectors:
- Smart Health & Wearables: Training predictive models for early disease detection, activity monitoring, or anomaly detection on personal health data from wearables (smartwatches, continuous glucose monitors) and medical IoT devices. This is done without ever sharing sensitive patient information with a central cloud, enabling personalized health insights while maintaining strict privacy.
- Smart Cities & Transportation: Optimizing traffic flow, predicting pollution levels, or detecting infrastructure anomalies from sensor data across city environments. FL can allow traffic cameras to collaboratively learn pedestrian detection models or smart streetlights to optimize energy consumption based on aggregated patterns, all without revealing individual movements or specific location data.
- Industrial IoT (IIoT) & Predictive Maintenance: Training models to predict equipment failures, optimize manufacturing processes, or enhance quality control using data from factory sensors and machinery. Companies can leverage FL to improve operational efficiency and reduce downtime without exposing proprietary operational data or sensitive production metrics to external entities.
- Smart Homes & Buildings: Personalizing energy management, enhancing security systems, or optimizing comfort settings based on household usage patterns. FL can train models for voice assistants to better understand individual accents, or for smart thermostats to learn occupant preferences, without sending raw voice commands, video feeds, or detailed occupancy data to the cloud.
- Mobile Keyboards & Voice Assistants: Improving predictive text, autocorrection, or speech recognition models based on individual user input patterns and language usage, directly on the device. Google's Gboard is a prominent example of FL improving user experience without compromising privacy.
- Autonomous Vehicles: Collaborative learning among vehicles to improve perception, navigation, and decision-making models. Vehicles can share model updates (e.g., refined object detection models) derived from their local sensor data, rather than transmitting massive and highly sensitive raw sensor data streams, accelerating the development of safer and more intelligent self-driving systems.
A Multidisciplinary Frontier for AI Practitioners and Enthusiasts
Federated Learning at the edge is not just a niche area; it represents a critical frontier in the evolution of AI. For practitioners and enthusiasts, it offers:
- Cutting-Edge Research Opportunities: With many open problems in areas like non-IID data handling, security, and resource optimization, there's ample room for novel contributions.
- High Impact: Solving the challenges in this domain has massive implications for privacy, scalability, and the practical deployment of AI in real-world, distributed systems, making AI more accessible and trustworthy.
- Multidisciplinary Learning: It seamlessly blends machine learning, distributed systems, cybersecurity, privacy engineering, and embedded systems, offering a holistic understanding of modern AI challenges.
- Practical Skill Development: Engaging with FL involves working with distributed computing frameworks (e.g., PyTorch, TensorFlow Federated), understanding communication protocols, and grappling with real-world data challenges, enhancing practical skills.
- Career Growth: Expertise in FL and Edge AI is becoming increasingly sought after across various industries, from tech giants to specialized IoT startups, creating significant career opportunities.
To delve deeper, exploring specific FL algorithms like FedAvg, FedProx, SCAFFOLD, or FedMA, understanding security techniques such as Differential Privacy, Secure Multi-Party Computation (SMC), and Homomorphic Encryption (HE), and experimenting with frameworks like TensorFlow Federated (TFF), PySyft, or Flower will provide invaluable insights.
The future of AI is distributed, private, and efficient. Federated Learning at the edge is not just a technological advancement; it's a foundational shift that will unlock the full potential of the Internet of Things, making AI ubiquitous, trustworthy, and truly transformative.