Federated Learning for Edge AI in IoT: Revolutionizing Data Privacy and Efficiency
Explore how Federated Learning (FL) is transforming AI deployment in IoT edge environments. This post delves into FL's core principles, addressing critical challenges like data privacy, bandwidth, and latency in distributed AI training.
The digital landscape is rapidly transforming, driven by the proliferation of Internet of Things (IoT) devices. From smart sensors in our homes to industrial machinery and autonomous vehicles, these devices generate an unprecedented volume of data at the "edge" of networks. Harnessing this data with Artificial Intelligence (AI) promises revolutionary insights and automation. However, deploying AI at the edge of IoT ecosystems presents formidable challenges: data privacy concerns, bandwidth limitations, latency issues, and the sheer scale and heterogeneity of devices.
Enter Federated Learning (FL) – a paradigm-shifting approach that is redefining how AI models are trained and deployed in distributed environments. By bringing the learning process closer to the data source, FL offers a compelling solution to many of the hurdles faced by traditional centralized AI training. This post will delve into the intricacies of Federated Learning for Edge AI in IoT, exploring its core principles, timely importance, recent advancements, and practical applications that are shaping the future of intelligent, privacy-preserving IoT.
The Confluence of IoT, Edge AI, and the Need for Federated Learning
IoT devices are the eyes and ears of our increasingly connected world. They collect everything from temperature readings and vibration data to sophisticated video feeds and biometric information. Processing this data locally, at the edge, rather than sending it all to a distant cloud, is the essence of Edge AI. This approach drastically reduces latency, conserves bandwidth, and enhances real-time decision-making.
However, training sophisticated AI models on this edge data traditionally involves either:
- Centralized Training: Collecting all raw data from potentially millions of devices and sending it to a central cloud server. This is a privacy nightmare, bandwidth-intensive, and often infeasible due to data volume and regulatory constraints.
- Local Training (Isolated): Training models independently on each device. While privacy-preserving, this approach misses the collective intelligence that could be gained from shared learning across devices, leading to suboptimal or slower model improvements.
Federated Learning emerges as a powerful third way, bridging the gap between these two extremes. It allows AI models to learn from the rich, diverse data residing on individual IoT devices without ever requiring that raw data to leave its local environment.
What is Federated Learning? A Paradigm Shift in ML Training
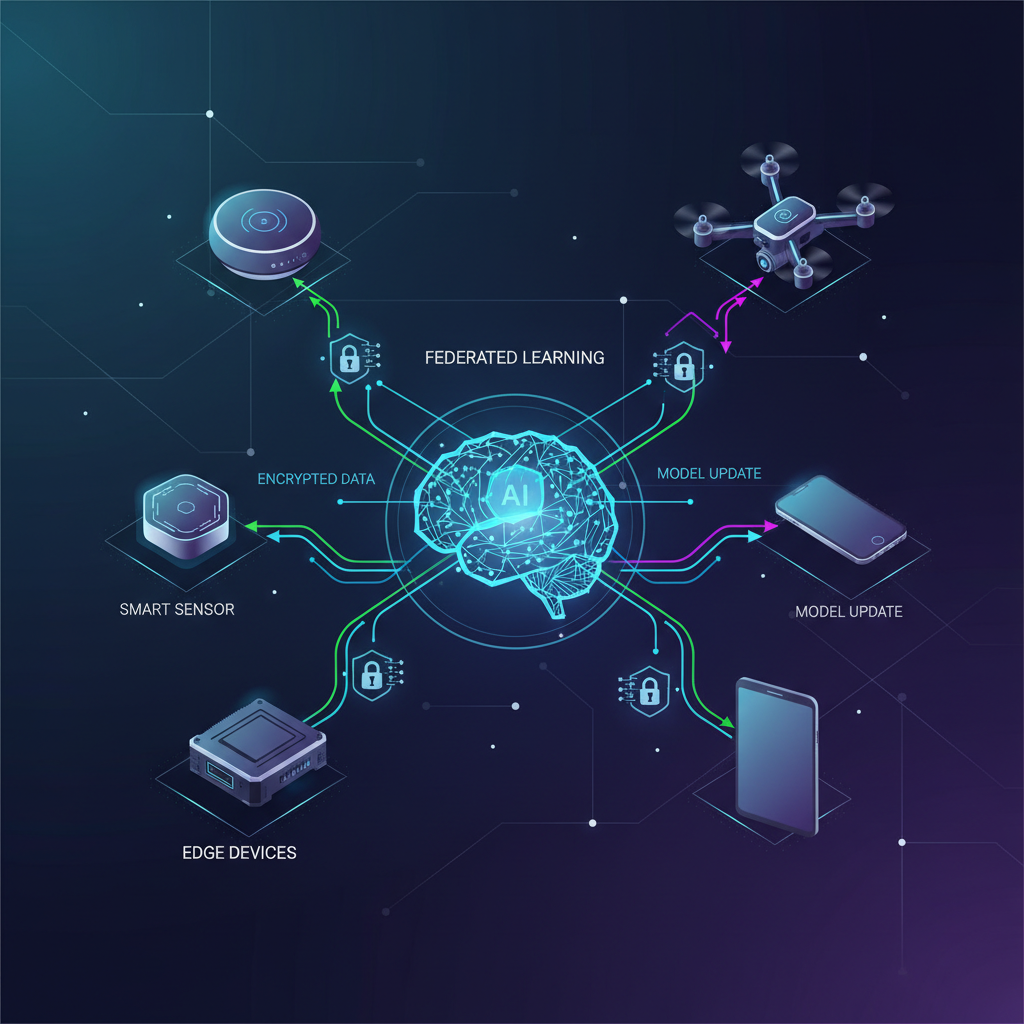
At its core, Federated Learning is a distributed machine learning approach where an algorithm is trained across multiple decentralized edge devices or servers. The defining characteristic is that data samples never leave their local storage. Instead, only model updates – such as gradients, weight parameters, or statistical summaries – are exchanged with a central server.
Let's break down the typical FL workflow:
- Initialization: A global model (e.g., a neural network) is initialized by a central server and distributed to a selected subset of participating edge devices (clients).
- Local Training: Each selected client trains the global model using its own local, private dataset. This training is performed entirely on the device, leveraging its computational resources.
- Model Update Transmission: After local training, instead of sending their raw data, each client sends its updated model parameters (or the differences/gradients from the global model) back to the central server.
- Global Aggregation: The central server aggregates these received model updates from multiple clients. The most common aggregation strategy is Federated Averaging (FedAvg), where the server computes a weighted average of the client models to create a new, improved global model.
- Global Model Distribution: The newly aggregated global model is then sent back to the clients, initiating the next round of local training.
This iterative process continues until the global model converges or a predefined number of training rounds are completed. The beauty of this approach lies in its ability to leverage distributed data while maintaining strict privacy boundaries.
Why Federated Learning is Crucial for Edge AI in IoT
The unique characteristics of IoT deployments make FL not just an attractive option, but often a necessary one.
- Data Privacy and Security: This is arguably the most significant driver. IoT devices frequently collect highly sensitive information – personal health data from wearables, surveillance footage from smart cameras, proprietary industrial process data. With stringent regulations like GDPR and CCPA, and growing user privacy concerns, FL ensures that AI models learn from this data without it ever leaving the device, drastically reducing privacy risks and the attack surface for data breaches.
- Bandwidth and Latency Reduction: Imagine a smart city with millions of sensors generating continuous data streams. Transmitting all this raw data to a central cloud for processing and training would overwhelm network infrastructure and incur massive costs. FL trains models at the edge, significantly reducing the need to send raw data. Only small model updates are transmitted, saving bandwidth and enabling faster, near real-time model improvements.
- Scalability: The sheer volume of IoT devices is exploding, projected to reach tens of billions in the coming years. A centralized training approach quickly becomes unmanageable at this scale. FL's inherently distributed architecture is designed for massive parallelism, making it highly scalable to millions or even billions of devices.
- Resource Constraints: Many IoT devices are resource-constrained, with limited computational power, memory, and battery life. While FL still requires local computation, algorithms are continually optimized for efficiency. Techniques like partial model updates, less frequent communication, and lightweight model architectures make FL viable even for constrained edge environments.
- Personalization: FL can facilitate highly personalized AI experiences. A global model can provide a strong general foundation, which is then fine-tuned locally on an individual user's device. This allows the model to adapt to specific usage patterns, environmental conditions, or individual preferences without compromising the privacy of their unique data.
- Regulatory Compliance: For industries with data localization requirements (e.g., healthcare, finance, government), FL offers a mechanism to train models collaboratively across different regions or jurisdictions without violating data sovereignty laws.
Recent Developments and Emerging Trends: Pushing the Boundaries of FL
The field of Federated Learning is dynamic, with researchers and practitioners constantly addressing its inherent challenges and expanding its capabilities.
1. Tackling Heterogeneity Challenges
IoT environments are inherently heterogeneous. Devices vary wildly in hardware capabilities, network connectivity, and the statistical distribution of their local data (known as non-IID or non-independent and identically distributed data). This non-IID nature is a major hurdle, as it can lead to model divergence or slower convergence if not handled properly.
- Adaptive FL Algorithms: Researchers are developing methods that dynamically adjust learning rates, client selection strategies, or aggregation techniques based on device capabilities and data characteristics. For instance, prioritizing clients with more diverse data or faster computation.
- Personalized Federated Learning (pFL): This is a rapidly growing sub-field aiming to learn a global model while simultaneously allowing for highly personalized local models. Techniques like FedPer, pFedMe, and MOCHA achieve this by learning a shared representation layer and a personalized head, or by allowing clients to fine-tune the global model with their local data for a few extra steps. This effectively addresses the non-IID data problem by allowing local customization.
- Hierarchical FL (HFL): In large-scale deployments, introducing intermediate aggregators (e.g., edge gateways, local servers) between individual devices and the central server can optimize communication and computation. HFL allows for localized aggregation within clusters of devices before sending summarized updates to the global server, reducing communication overhead and improving scalability.
2. Enhancing Security and Robustness
While FL inherently offers privacy benefits, it's not immune to sophisticated attacks. Research is focused on bolstering its security and robustness:
- Differential Privacy (DP): Integrating DP mechanisms involves adding carefully calibrated noise to model updates before they are sent to the central server. This provides a quantifiable privacy guarantee, making it extremely difficult for an attacker (even the central server) to infer information about individual client data from the aggregated updates.
- Secure Aggregation (SA): Cryptographic techniques are employed to ensure that the central server can only compute the aggregated sum of model updates, without ever seeing individual client updates. Techniques like homomorphic encryption (which allows computations on encrypted data) and secure multi-party computation (SMC) are being explored to achieve this, providing stronger privacy guarantees against a malicious central server.
- Byzantine Robustness: This addresses the threat of malicious or faulty clients sending corrupted or intentionally misleading model updates (known as data poisoning or model poisoning attacks). Algorithms are being developed that can detect and mitigate the impact of such Byzantine clients, ensuring the integrity and convergence of the global model.
3. Resource-Efficient FL for Constrained Environments
The resource limitations of many IoT devices necessitate highly efficient FL algorithms.
- Quantization and Pruning: Model compression techniques reduce the size and complexity of neural networks. Quantization reduces the precision of model weights (e.g., from 32-bit floating point to 8-bit integers), while pruning removes less important connections or neurons. These techniques reduce the size of model updates transmitted and the computational load on edge devices.
- Communication Efficiency: The biggest bottleneck in FL is often communication. Techniques like sparsification (sending only the most significant model updates), sketching (creating compressed representations of updates), and gradient compression (reducing the bit-width of gradients) minimize the amount of data transmitted during aggregation rounds.
- Asynchronous FL: Traditional FL often operates in synchronous rounds, where the central server waits for a predefined number of clients before aggregating. In unreliable IoT networks with varying device availability, this can be inefficient. Asynchronous FL allows clients to send updates at their own pace, and the server aggregates them as they arrive, making the system more resilient and efficient in dynamic environments.
4. Integration with TinyML
Extending FL to extremely resource-constrained microcontrollers, often referred to as TinyML devices, is an active area. This involves developing highly optimized FL frameworks, extremely lightweight model architectures, and novel communication protocols tailored for devices with kilobytes of RAM and limited processing power.
5. New Application Domains
Beyond its initial applications in mobile keyboard prediction, FL is now being explored across a vast array of IoT domains:
- Industrial IoT (IIoT): Predictive maintenance, anomaly detection on factory floors, quality control in manufacturing.
- Smart Cities: Traffic management, environmental monitoring, smart lighting optimization, public safety.
- Healthcare IoT: Remote patient monitoring, personalized health insights from wearables, drug discovery, medical image analysis.
- Autonomous Vehicles: Collaborative learning for perception, navigation, and predictive driving without sharing raw sensor data between vehicles or with a central cloud.
Practical Applications for AI Practitioners and Enthusiasts
Let's explore some concrete examples of how Federated Learning is being applied in the real world, demonstrating its transformative potential.
1. Predictive Maintenance in Industrial IoT (IIoT)
Scenario: A large manufacturing plant operates hundreds of complex machines (e.g., CNC machines, robotic arms, turbines). Each machine is equipped with various sensors collecting operational data like vibration, temperature, pressure, and current. The goal is to predict equipment failures before they occur, minimizing downtime and maintenance costs.
FL Application: Instead of sending terabytes of raw sensor data from each machine to a central cloud, each machine's onboard edge gateway (or a nearby industrial PC) trains a local fault prediction model (e.g., a deep learning model for anomaly detection) using its own sensor data. When a training round is complete, only the updated model parameters (not the raw data) are sent to a central server within the factory or to a secure cloud aggregator. This central server aggregates updates from all machines to create a robust global model that captures common failure patterns across the entire plant. This global model is then pushed back to all individual machines, improving their local predictive capabilities.
Benefit:
- Reduced Downtime: More accurate and timely predictions lead to proactive maintenance, preventing costly breakdowns.
- Optimized Maintenance Schedules: Maintenance can be scheduled precisely when needed, rather than on fixed intervals, saving resources.
- Enhanced Data Privacy: Proprietary manufacturing processes and sensitive operational data remain on the factory floor, complying with industrial security standards and competitive concerns.
- Scalability: Easily extendable to thousands of machines across multiple plants without overwhelming network infrastructure.
2. Smart Healthcare Wearables for Personalized Health Monitoring
Scenario: Millions of individuals use smartwatches, fitness trackers, and other wearable health devices that continuously collect sensitive biometric data (heart rate, sleep patterns, activity levels, blood oxygen, etc.). The aim is to provide personalized health insights, early disease detection, and tailored wellness recommendations.
FL Application: Each user's wearable device trains a personalized health anomaly detection model or activity recognition model based on their unique physiological data and daily routines. For instance, a model might learn to detect deviations from a user's normal heart rate variability during sleep. Periodically, these devices send only their model updates (e.g., changes in model weights that reflect new health patterns) to a healthcare provider's secure server or a research institution's aggregator. The central server aggregates these updates to improve a global model for broader disease prediction or personalized health recommendations. This enhanced global model is then sent back to the devices, allowing them to refine their local, personalized models further.
Benefit:
- Highly Personalized Health Insights: Models adapt to individual physiology and lifestyle, providing more accurate and relevant health advice.
- Strong Compliance with HIPAA/GDPR: Raw patient data never leaves the individual's device, ensuring robust privacy and compliance with strict healthcare data regulations.
- Early Detection of Health Issues: Collaborative learning across a large user base can help identify subtle health markers indicative of emerging conditions.
- Research Acceleration: Researchers can leverage insights from vast, diverse datasets without direct access to sensitive patient information.
3. Smart Home Automation and Personalized Experiences
Scenario: A modern smart home contains numerous interconnected devices: smart thermostats, lighting systems, voice assistants, security cameras, and smart appliances. These devices collect data about user behavior, preferences, and environmental conditions. The goal is to create a more responsive, intuitive, and personalized home environment.
FL Application: Instead of sending raw audio recordings to the cloud for voice assistant training, or continuous video streams for occupancy detection, each smart home device can train local models. For example, a smart thermostat learns a user's preferred temperature schedules based on their interactions, while a voice assistant trains its speech recognition model on local voice commands. These devices then send model updates (e.g., refined parameters for temperature prediction or improved acoustic models) to a central home hub or a secure cloud service. The central entity aggregates these updates to improve a global model for general home automation intelligence (e.g., recognizing common voice commands, optimizing energy usage patterns). This improved global model is then distributed back to all devices, enhancing their local intelligence.
Benefit:
- Enhanced Privacy for Residents: Raw audio, video, and personal usage data remain within the home, addressing significant privacy concerns associated with smart home technology.
- More Responsive and Personalized Automation: Devices learn and adapt to individual habits and preferences faster and more accurately.
- Reduced Internet Bandwidth Usage: No need to constantly stream large amounts of raw data to the cloud.
- Improved Device Interoperability: Devices can collaboratively learn from each other's data patterns to create a more cohesive smart home experience.
4. Autonomous Vehicle Fleets for Collaborative Learning
Scenario: A fleet of self-driving cars operates in diverse urban and rural environments, continuously collecting vast amounts of sensor data (Lidar, radar, cameras, ultrasonic sensors) about road conditions, traffic patterns, obstacles, and pedestrian behavior. The challenge is to rapidly improve the perception and navigation capabilities of the entire fleet.
FL Application: Each autonomous vehicle trains local perception or prediction models based on its immediate surroundings and driving experiences. For instance, a car might encounter a new type of road hazard or a unique traffic scenario. Instead of sending all its raw sensor data to a central data center, the vehicle sends only its model updates (e.g., refined weights for object detection or improved parameters for predicting pedestrian intent) to a central server. This server aggregates updates from hundreds or thousands of vehicles across the fleet, synthesizing new knowledge about diverse driving conditions, rare events, or improved object recognition. The enhanced global model is then distributed back to all vehicles, allowing them to learn from the collective experience of the entire fleet without ever sharing sensitive raw data about specific routes or locations.
Benefit:
- Faster Learning from Diverse Real-World Scenarios: The fleet collectively learns from a wider range of driving conditions and rare events, accelerating model improvement.
- Improved Safety: Enhanced perception and prediction capabilities lead to safer autonomous driving.
- Reduced Data Transmission Costs: Significantly lowers the bandwidth required compared to sending raw sensor data from every vehicle.
- Privacy for Specific Routes or Locations: Raw data, which might reveal sensitive operational details or user travel patterns, remains on the vehicle.
Challenges and Future Directions
While Federated Learning offers immense promise, several challenges remain to be fully addressed before widespread, robust deployment:
- Data Heterogeneity (Non-IID Data): This remains a significant technical challenge. While personalized FL techniques are emerging, developing universally robust and efficient solutions for highly skewed data distributions is crucial.
- System Heterogeneity: Managing devices with vastly different computational power, battery life, and network connectivity requires sophisticated client selection, scheduling, and adaptive aggregation strategies.
- Security and Trust: While FL enhances privacy, ensuring the integrity of model updates against poisoning attacks and protecting against inference attacks (even with DP) remains an active research area. Building trust in FL systems, especially in critical applications, is paramount.
- Regulatory Frameworks: As FL gains traction, developing clear legal and ethical guidelines for its deployment, especially in sensitive domains like healthcare and finance, will be essential.
- Debugging and Explainability: Debugging distributed FL models and understanding their decisions can be far more complex than with centralized models, posing challenges for model validation and trustworthiness.
- Real-world Deployment and Standardization: Moving from theoretical research and proof-of-concept implementations to robust, production-ready FL systems for diverse IoT environments requires standardized frameworks, tools, and best practices.
Conclusion
Federated Learning for Edge AI in IoT is not merely an academic pursuit; it represents a fundamental shift in how artificial intelligence will be deployed and managed in our increasingly interconnected world. Its unique ability to balance powerful AI capabilities with critical privacy, efficiency, and scalability requirements positions it as a cornerstone technology for the future of intelligent IoT ecosystems.
For AI practitioners and enthusiasts, understanding and contributing to this rapidly evolving field offers immense opportunities. From developing more robust algorithms to designing privacy-preserving architectures and exploring novel application domains, the potential to build innovative, ethical, and impactful solutions is vast. As IoT devices continue to proliferate and data privacy becomes an ever-greater concern, Federated Learning will undoubtedly play a pivotal role in unlocking the full potential of AI at the edge, ushering in an era of truly intelligent, secure, and personalized experiences.