Federated Learning for Edge AI: Unlocking IoT Potential with Privacy
Explore how Federated Learning revolutionizes AI at the edge, addressing critical challenges like data privacy and efficient processing in IoT environments. Discover its practical applications and transformative potential.
The digital world is expanding beyond our screens and into the physical environment, driven by the proliferation of Internet of Things (IoT) devices. From smart sensors monitoring our cities to industrial machinery optimizing production lines, these devices are generating an unprecedented deluge of data at the "edge" of the network. Harnessing this data with Artificial Intelligence promises transformative insights and automation. However, this powerful synergy introduces significant challenges: how do we process vast quantities of data efficiently, respect user privacy, and operate within the constraints of edge environments? The answer lies in a revolutionary paradigm: Federated Learning for Privacy-Preserving Edge AI in IoT.
This isn't just a theoretical concept; it's a critical, timely, and intensely practical solution that addresses the core dilemmas of modern AI deployment. It allows us to unlock the full potential of AI at the edge without compromising the fundamental principles of data privacy and operational efficiency.
The Confluence of Challenges at the Edge
Before diving into Federated Learning (FL), it's crucial to understand the landscape of challenges that make it so indispensable for IoT and Edge AI:
-
The Data Explosion at the Edge: IoT devices are everywhere, from wearables tracking health metrics to cameras monitoring public spaces and industrial sensors predicting equipment failure. Each generates continuous streams of data. Sending all this raw data back to centralized cloud servers for AI training is often impractical due to:
- Bandwidth Limitations: Uploading terabytes of video or sensor data from thousands of devices can saturate networks, especially in remote or bandwidth-constrained locations.
- Latency: Real-time AI applications (e.g., autonomous vehicles, critical infrastructure monitoring) cannot afford the round-trip delay of sending data to the cloud, processing it, and receiving an inference.
- Cost: Cloud storage and data transfer costs can quickly become prohibitive for massive IoT deployments.
-
Mounting Privacy and Regulatory Concerns: Much of the data generated by IoT devices is inherently sensitive. Consider personal health data from wearables, location data from smart vehicles, surveillance footage from security cameras, or proprietary operational data from industrial machinery. Centralized collection of such data for AI training raises significant privacy red flags and falls under strict regulations like GDPR, CCPA, and HIPAA. Breaches of this sensitive data can lead to severe financial penalties, reputational damage, and erosion of public trust.
-
Evolving Edge Device Capabilities: Historically, edge devices were seen as mere data collectors. However, advancements in hardware, such as specialized AI accelerators (e.g., NPUs, TPUs, GPUs) and more powerful microcontrollers, mean that modern edge devices are increasingly capable of performing local AI inference and even limited training. This computational shift makes distributed learning paradigms not just desirable, but feasible.
These challenges collectively highlight a fundamental tension: the need for data to train powerful AI models versus the imperative to protect privacy and operate efficiently at scale. Federated Learning emerges as the elegant solution to this dilemma.
Federated Learning: A Paradigm Shift for Distributed AI
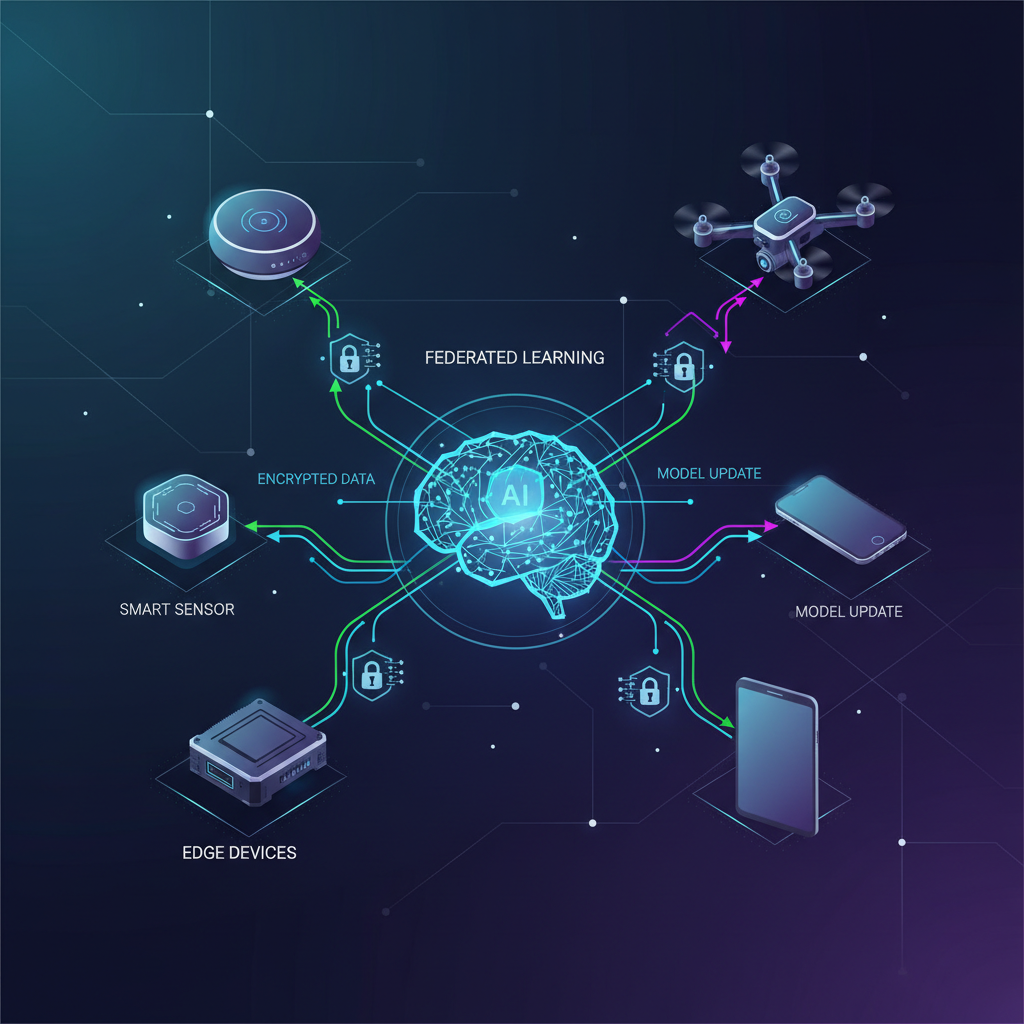
Federated Learning is a decentralized machine learning approach that enables multiple participants – such as individual IoT devices, edge gateways, or even entire organizations – to collaboratively train a shared global AI model without ever exchanging their raw local data. The core idea is to bring the computation to the data, rather than the data to the computation.
Here's a breakdown of how it works:
-
Initialization: A central server (or an orchestrator) initializes a global AI model (e.g., a neural network) and sends it to a selected subset of participating IoT devices or edge nodes.
-
Local Training (on Device): Each selected device downloads the current global model. It then trains this model locally using its own private, resident dataset. This training process is identical to how a model would be trained in a centralized setting, but it happens entirely on the device, leveraging its local computational resources. Crucially, the raw data never leaves the device's secure environment.
-
Model Updates (not Data) Transmission: Instead of sending its raw data back to the central server, each device computes and sends only the model updates (e.g., gradients, weight differences, or learned parameters) that resulted from its local training. These updates are typically much smaller in size than the raw datasets.
-
Secure Aggregation: The central server receives these model updates from numerous participating devices. It then aggregates these updates to create an improved version of the global model. The simplest and most common aggregation method is Federated Averaging (FedAvg), where the server computes a weighted average of the received model parameters. More complex, privacy-preserving aggregation techniques can also be employed (e.g., secure multi-party computation).
-
Global Model Distribution: The newly aggregated, improved global model is then sent back to the devices for the next round of local training.
-
Iterative Refinement: This entire process repeats iteratively over many rounds. With each round, the global model progressively learns from the collective experience of all participating devices, improving its accuracy and generalization capabilities, all while the sensitive raw data remains decentralized and private.
Key Advantages for IoT & Edge AI
The FL paradigm offers compelling benefits that directly address the challenges outlined earlier:
- Privacy Preservation: This is the cornerstone advantage. Raw, sensitive data never leaves the device. Only aggregated, anonymized model updates are shared, significantly enhancing data privacy and simplifying compliance with stringent regulations.
- Reduced Bandwidth Consumption: By transmitting only compact model updates instead of voluminous raw datasets, FL drastically cuts down on network traffic, making it viable for bandwidth-constrained edge environments and reducing operational costs.
- Lower Latency: AI inference can occur directly on the edge device, eliminating the need for data to travel to the cloud and back. While training still involves communication, the local training component reduces overall latency for model improvement.
- Robustness to Data Heterogeneity (Non-IID Data): Real-world IoT deployments often feature non-IID data, meaning data distributions vary significantly across devices (e.g., a smart camera in a park sees different patterns than one in a factory). FL algorithms are designed to handle this heterogeneity, leading to more robust and generalizable global models.
- Enhanced Scalability: FL can scale to an enormous number of devices without overwhelming a central data store or processing unit, as the computational burden is distributed across the edge network.
- Data Freshness: Models can be continuously updated with the latest data generated at the edge, ensuring they remain relevant and accurate without constant data uploads.
Recent Developments & Emerging Trends
Federated Learning is a vibrant research area, constantly evolving to meet new demands and overcome existing limitations.
- Resource-Constrained FL (TinyML-FL): Adapting FL algorithms for highly constrained devices (microcontrollers, tiny sensors) with limited compute, memory, and battery power. This involves techniques like model quantization (reducing precision), sparsification (reducing model size), and highly efficient communication protocols.
- Personalized Federated Learning: A single global model might not be optimal for every device, especially with highly non-IID data. Personalized FL aims to create customized models for each client while still benefiting from the collective knowledge of the global model. This often involves fine-tuning the global model locally or learning a small personalized layer.
- Advanced Security and Trust Mechanisms:
- Homomorphic Encryption (HE) & Secure Multi-Party Computation (SMC): These cryptographic techniques allow computations (like aggregation of model updates) to be performed on encrypted data without decrypting it. This provides strong privacy guarantees, even against a malicious central server.
- Differential Privacy (DP): By adding carefully calibrated noise to model updates or the aggregated model, DP mathematically guarantees that the presence or absence of any single data point in the training set cannot be inferred, protecting against inference attacks.
- Adversarial Robustness: Research focuses on defending against poisoning attacks (malicious devices sending corrupted updates to degrade the global model) and backdoor attacks (inserting hidden vulnerabilities into the model).
- Communication Efficiency Enhancements: Further reducing communication overhead is critical. Techniques include:
- Model Compression: Quantization, pruning, and sparsification of model updates before transmission.
- Asynchronous Update Schemes: Allowing devices to send updates at their own pace, rather than waiting for a synchronized round.
- Client Selection Strategies: Intelligently selecting which devices participate in each training round based on data quality, connectivity, or computational resources.
- Vertical Federated Learning (VFL): While horizontal FL (same feature space, different data instances) is common, VFL addresses scenarios where different organizations hold complementary feature sets about the same entities (e.g., a bank and an e-commerce site having different data about the same customer). VFL allows collaborative model training without sharing raw feature data.
- Edge Aggregation & Hierarchical FL: Instead of a single central cloud server, local edge gateways can aggregate updates from nearby devices (e.g., all smart cameras in a building). These aggregated results are then sent to a higher-level server for further aggregation, creating a hierarchical FL architecture. This multi-tier approach further reduces latency and bandwidth to the cloud, enhancing local autonomy.
- Integration with Blockchain: Blockchain can provide a transparent, immutable ledger for recording model updates, client participation, and aggregation processes, enhancing trust and auditability in FL systems.
Practical Applications Across Industries
The implications of Federated Learning for Edge AI are vast, enabling new applications that were previously impossible due to privacy or operational constraints.
- Smart Cities:
- Traffic Management: AI models trained on local traffic sensor data from different intersections can optimize traffic light timings and flow without sharing sensitive vehicle movement data across municipal boundaries or with cloud providers.
- Environmental Monitoring: Collaboratively training pollution prediction models using data from distributed air quality sensors, allowing for localized insights without centralizing sensitive environmental readings.
- Healthcare & Wearables:
- Personalized Health Monitoring: Training diagnostic or anomaly detection models on individual wearable device data (heart rate, activity, sleep patterns) to identify health risks or provide personalized coaching, all without sending sensitive patient data to a central server.
- Drug Discovery: Pharmaceutical companies can collaborate on research by training models on their proprietary patient or compound datasets, pooling insights without revealing sensitive competitive information.
- Industrial IoT (IIoT):
- Predictive Maintenance: Training models on sensor data from machinery across different factories to predict equipment failures. Each factory's operational data remains private, but the global model benefits from a diverse range of failure patterns.
- Quality Control: AI models learning from camera feeds on production lines across various manufacturing plants to detect defects, improving overall quality without centralizing proprietary manufacturing processes.
- Smart Homes & Consumer Electronics:
- Voice Assistants: Improving speech recognition and natural language understanding models by learning from user interactions directly on individual smart speakers, without recording and sending private conversations to the cloud.
- Personalized Recommendations: Training recommendation engines for content (movies, music) or products directly on smart TVs or streaming boxes, tailoring suggestions based on local user preferences without sharing viewing history.
- Autonomous Vehicles:
- Collaborative Perception: Vehicles can share model updates trained on local sensor data (cameras, LiDAR, radar) to improve object detection, scene understanding, and predictive capabilities for all vehicles in a fleet, without sharing raw driving footage, which is often highly sensitive.
Challenges for Practitioners
While the promise of FL is immense, its implementation comes with its own set of practical challenges that practitioners must navigate:
- Non-IID Data: Handling data distributions that vary significantly across devices (the "non-IID" problem) can degrade the performance and convergence speed of the global model. This often requires specialized aggregation algorithms and more sophisticated training strategies.
- System Heterogeneity: IoT devices vary widely in computational power, memory, network connectivity, and battery life. Managing client selection, scheduling, and ensuring fair participation across such diverse hardware is complex.
- Communication Overhead: Although significantly reduced compared to raw data transfer, communication remains a bottleneck, especially for frequent updates or a very large number of clients. Optimizing communication efficiency is a continuous effort.
- Security & Privacy Guarantees: Implementing robust cryptographic techniques like homomorphic encryption or secure multi-party computation can be computationally expensive and complex to integrate effectively. Ensuring true privacy against sophisticated inference attacks and malicious participants is an ongoing research and engineering challenge.
- Model Convergence: Achieving stable and efficient convergence of the global model can be more challenging in a distributed FL environment compared to centralized training, especially with non-IID data and intermittent client availability.
- Debugging and Interpretability: Debugging issues, identifying problematic clients, and interpreting model behavior in a distributed, opaque FL environment is significantly harder than in a centralized setting.
- Deployment and Orchestration: Managing and orchestrating FL training across thousands or even millions of geographically dispersed edge devices requires robust infrastructure, sophisticated client management, and fault tolerance mechanisms.
Tools and Frameworks for Federated Learning
Fortunately, a growing ecosystem of open-source tools and frameworks is emerging to help practitioners build and deploy FL solutions:
- TensorFlow Federated (TFF): Developed by Google, TFF is an open-source framework specifically designed for implementing federated learning. It provides a high-level API for expressing FL computations and a low-level API for custom federated algorithms, suitable for both research and production.
- PySyft (OpenMined): A library for secure, private machine learning, including FL. PySyft integrates with popular ML frameworks (PyTorch, TensorFlow) and focuses on techniques like differential privacy, homomorphic encryption, and secure multi-party computation to enhance privacy.
- Flower: A framework for federated learning that prides itself on being framework-agnostic (supporting PyTorch, TensorFlow, JAX, Scikit-learn, etc.). Flower focuses on flexibility, extensibility, and ease of use, allowing researchers and developers to quickly prototype and deploy FL systems.
- NVIDIA FLARE (Federated Learning Application Runtime Environment): An open-source SDK from NVIDIA designed for building FL applications. FLARE is domain-agnostic and provides a robust runtime environment for orchestrating FL workflows, particularly useful in medical imaging and healthcare.
Conclusion
Federated Learning for Privacy-Preserving Edge AI in IoT is not merely a buzzword; it represents a fundamental shift in how we approach AI development and deployment in an increasingly connected and privacy-conscious world. It elegantly reconciles the insatiable demand for powerful AI with the critical imperatives of data privacy, operational efficiency, and regulatory compliance.
For AI practitioners, researchers, and enthusiasts, understanding and engaging with FL is no longer optional. Its algorithmic nuances, security challenges, and practical deployment strategies are becoming indispensable knowledge. As IoT devices continue to proliferate and edge computing matures, Federated Learning will undoubtedly serve as a cornerstone technology, unlocking a new generation of intelligent, ethical, and scalable AI applications that respect our data and enhance our lives. The future of AI is distributed, private, and at the edge, and Federated Learning is leading the way.